# Tony Kipkemboi
> AI Engineer and Content Creator specializing in AI automations, agent systems, and developer education. US Army veteran. Former CrewAI, Snowflake, Bloomberg, Booz Allen Hamilton.
I build AI automations and agent systems that help teams work smarter. I create technical content about AI across social platforms including YouTube, where my most popular video on building PDF RAG systems with Ollama has 189K+ views.
I've spoken at PyCon US, ODSC, Harvard Kennedy School, IBM TechXchange, MLOps World, and more. I'm passionate about open-source software, AI agents, and developer education.
## Contact & Social
- Website: https://tonykipkemboi.com
- GitHub: https://github.com/tonykipkemboi
- YouTube: https://www.youtube.com/@tonykipkemboi
- LinkedIn: https://linkedin.com/in/tonykipkemboi
- X/Twitter: https://x.com/tonykipkemboi
- RSS Feed: https://tonykipkemboi.com/rss
## Expertise
- AI Agents & Multi-Agent Systems (CrewAI, LangChain, LlamaIndex)
- RAG (Retrieval-Augmented Generation)
- Python, Streamlit, Next.js
- Local LLMs (Ollama, Groq)
- Developer Education & Technical Content Creation
## Background
- US Army Veteran
- Former Developer Advocate at CrewAI
- Former Snowflake
- Former Bloomberg
- Former Booz Allen Hamilton
- University of Pennsylvania (Penn Engineering)
---
## Open Source Projects
### Ollama PDF RAG (504 GitHub stars)
A locally-hosted RAG (Retrieval-Augmented Generation) system that allows users to chat with their PDF documents using Ollama and LangChain. Features include document chunking, vector embeddings, and semantic search.
- Link: https://github.com/tonykipkemboi/ollama_pdf_rag
- GitHub: https://github.com/tonykipkemboi/ollama_pdf_rag
- Tech: Python, Ollama, LangChain, Streamlit, ChromaDB
### CrewAI Gmail Automation (186 GitHub stars)
Automate Gmail inbox management using CrewAI agents. Intelligently categorizes, responds to, and organizes emails using AI-powered workflows.
- Link: https://github.com/tonykipkemboi/crewai-gmail-automation
- GitHub: https://github.com/tonykipkemboi/crewai-gmail-automation
- Tech: Python, CrewAI, Gmail API, LangChain
### Resume Optimization Crew (148 GitHub stars)
AI-powered resume optimization system using CrewAI. Analyzes and enhances resumes to match job descriptions and ATS requirements.
- Link: https://github.com/tonykipkemboi/resume-optimization-crew
- GitHub: https://github.com/tonykipkemboi/resume-optimization-crew
- Tech: Python, CrewAI, AI Optimization
### Trip Planner Agent (141 GitHub stars)
CrewAI agents that can plan your vacation. Uses multi-agent collaboration to create detailed itineraries based on your preferences.
- Link: https://github.com/tonykipkemboi/trip_planner_agent
- GitHub: https://github.com/tonykipkemboi/trip_planner_agent
- Tech: Python, CrewAI, Streamlit, LangChain
### Streamlit Replicate Image App (102 GitHub stars)
Image generation application built with Streamlit and Replicate API. Generate AI images using various models through an intuitive interface.
- Link: https://github.com/tonykipkemboi/streamlit-replicate-img-app
- GitHub: https://github.com/tonykipkemboi/streamlit-replicate-img-app
- Tech: Python, Streamlit, Replicate, Image Generation
### Groq Streamlit Demo (85 GitHub stars)
Demo showcasing Groq's ultra-fast LLM inference with Streamlit. Experience lightning-fast AI responses in an interactive web interface.
- Link: https://github.com/tonykipkemboi/groq_streamlit_demo
- GitHub: https://github.com/tonykipkemboi/groq_streamlit_demo
- Tech: Python, Groq, Streamlit, LLM
### Ollama Streamlit Demos (82 GitHub stars)
Collection of Streamlit demos showcasing various Ollama local LLM capabilities. Run AI models locally with no API keys required.
- Link: https://github.com/tonykipkemboi/ollama_streamlit_demos
- GitHub: https://github.com/tonykipkemboi/ollama_streamlit_demos
- Tech: Python, Ollama, Streamlit, Local LLM
### CrewAI Streamlit Demo (69 GitHub stars)
Demo showcasing how to output CrewAI agent task outputs on the Streamlit UI.
- Link: https://github.com/tonykipkemboi/crewai-streamlit-demo
- GitHub: https://github.com/tonykipkemboi/crewai-streamlit-demo
- Tech: Python, CrewAI, Streamlit
### Research Paper to Podcast (68 GitHub stars)
Automated system that transforms academic research papers into engaging podcast conversations using CrewAI and ElevenLabs.
- Link: https://github.com/tonykipkemboi/research-paper-to-podcast
- GitHub: https://github.com/tonykipkemboi/research-paper-to-podcast
- Tech: Python, CrewAI, ElevenLabs
### YouTube Yapper Trapper (67 GitHub stars)
Extract and analyze YouTube video transcripts. Perfect for researchers, content creators, and anyone who wants to quickly digest video content.
- Link: https://github.com/tonykipkemboi/youtube_yapper_trapper
- GitHub: https://github.com/tonykipkemboi/youtube_yapper_trapper
- Tech: Python, YouTube API, Transcription
---
## Speaking & Media Appearances
### MLOps World Conference - Austin
- Type: talk
- Source: MLOps World
- Date: 2025-10-08
- Link: https://mlopsworld.com/speakers/
Speaker demonstrating how agent orchestration, paired with rigorous evaluation, accelerates the path from prototype to production.
### IBM TechXchange Conference
- Type: talk
- Source: IBM
- Date: 2025-10-06
- Link: https://www.linkedin.com/posts/tonykipkemboi_ibmtechxchange-activity-7381001218820681728-Njde/
Speaker discussing AI agents and enterprise AI adoption strategies.
### Building AI Agents with CrewAI - DataCamp Course
- Type: course
- Source: DataCamp
- Date: 2025-10-01
- Link: https://www.datacamp.com/courses/building-ai-agents-with-crewai
Comprehensive course teaching developers how to build AI agent systems with CrewAI.
### Creating a Podcast Generation AI Multi-Agent - DataCamp Code-Along
- Type: course
- Source: DataCamp
- Date: 2025-08-13
- Link: https://www.datacamp.com/code-along/creating-a-podcast-generation-ai-multi-agent-with-crew-ai
Interactive code-along tutorial teaching how to use CrewAI to build a multi-agent system.
### ODSC AI X Podcast - AI Agents
- Type: podcast
- Source: Open Data Science Conference
- Date: 2025-06-11
- Link: https://podcasts.apple.com/us/podcast/odsc-east-2025-minisodes/id1721516836?i=1000712490491
Featured on ODSC's AI X Podcast discussing foundational AI agent building skills.
### Convergence 2025 - GenAI Engineering Conference
- Type: talk
- Source: Comet ML
- Date: 2025-05-13
- Link: https://www.comet.com/site/about-us/news-and-events/events/convergence-2025/
Speaking at Comet's virtual conference on GenAI Engineering.
### Build agentic systems with CrewAI and Amazon Bedrock
- Type: article
- Source: AWS Machine Learning Blog
- Date: 2025-03-31
- Link: https://aws.amazon.com/blogs/machine-learning/build-agentic-systems-with-crewai-and-amazon-bedrock/
Co-authored AWS ML Blog post on building agentic systems with CrewAI and Amazon Bedrock.
### ODSC East 2025 Workshop
- Type: talk
- Source: Open Data Science Conference
- Date: 2025-05-13
- Link: https://odsc.com/boston/
Led workshop on 'Agentic AI in Action: Build Autonomous, Multi-Agent Systems Hands-On in Python'.
### Guest Lecture at Harvard Kennedy School
- Type: talk
- Source: Harvard University
- Date: 2025-02-27
- Link: https://www.linkedin.com/posts/tonykipkemboi_aiagents-hks-activity-7301069792810008576-H7os/
Guest speaker on AI agents for Prof. Hu's data and information visualization class.
### PyCon US 2024
- Type: talk
- Source: PyCon US
- Date: 2024-05-15
- Link: https://us.pycon.org/2024/speaker/profile/90/index.html
Selected speaker at PyCon US 2024, the largest annual gathering for the Python programming community.
---
## Blog Posts
### Text Measurement Without the DOM
- Published: 2026-03-30
- Category: Developer Tools
- Tags: JavaScript, Developer Tools, Performance
- URL: https://tonykipkemboi.com/blog/pretext-text-measurement
A tiny JS library that calculates text height at any width without touching the DOM. Built by the creator of react-motion.
#### Full Content
via [@_chenglou](https://x.com/_chenglou/status/2037713766205608234)
Came across [pretext](https://github.com/chenglou/pretext) on X this weekend and spent some time playing with it.
It solves a specific problem: calculating how tall a block of text will be at a given width, without rendering it in the DOM. Normally you'd have to put the text in a div, measure `offsetHeight`, and deal with the reflow cost. Pretext does it in pure JavaScript using the browser's font engine via an off-screen canvas.
Two functions. **`prepare(text, font)`** measures all the word segments once. **`layout(prepared, width, lineHeight)`** calculates the height at any width. The prepare step is the expensive one. The layout step runs in about 0.09ms for 500 texts, so you can call it on every resize without thinking about it.
Built by [Cheng Lou](https://github.com/chenglou), who created react-motion. Few KB, supports all languages including RTL and CJK, validated against the Great Gatsby rendered across browsers.
## Try it
Type something, drag the width slider, see the numbers update. Left side is pretext (no DOM). Right side is the actual rendered text.
## Where this is useful
Virtualized lists where you need item heights before rendering. Canvas or WebGL text where there is no DOM. Preventing layout shift by calculating dimensions before painting. AI-driven UI testing where you want to verify layout without a browser.
Where it is not useful: static sites, server-rendered pages, anything where the text is already in the DOM and you can just read `offsetHeight`.
## Install
```bash
npm install @chenglou/pretext
```
```typescript
import { prepare, layout } from '@chenglou/pretext'
const prepared = prepare('Your text here', '16px sans-serif')
const result = layout(prepared, 400, 24) // width, lineHeight
console.log(result.height) // pixel height
```
Writing this mostly so I remember to reach for it next time I need text measurement in a project. If you are building anything with virtualized lists or canvas text, worth bookmarking.
Source: [github.com/chenglou/pretext](https://github.com/chenglou/pretext)
---
### AI Agent Skills and Plugins Explained (2026)
- Published: 2026-03-27
- Category: AI Agents
- Tags: AI Agents, Agent Skills, Plugins, Enterprise AI
- URL: https://tonykipkemboi.com/blog/agent-skills-and-plugins-explained
Skills are reusable instructions for AI tools. Plugins bundle them for distribution. Almost every major AI tool uses the same format.
#### Full Content
Two terms keep coming up in AI tooling conversations: skills and plugins. They sound similar. They are not.
A **skill** is a set of instructions that tells an AI tool how to do one specific task. A **plugin** bundles multiple skills (and other components) into a package you can install and share. Skill is the recipe. Plugin is the cookbook.
Both matter because they change how organizations scale AI adoption. Instead of every person writing their own prompts from scratch, you write a skill once and everyone uses it.
## What a skill looks like
A skill is a folder with one file: `SKILL.md`. Plain markdown. No programming required.
```yaml
---
name: review-pr
description: Review a pull request for security, tests, and style violations
---
# Pull Request Review
1. Read the diff of the current pull request.
2. Check for common security issues.
3. Verify that new functions have tests.
4. Flag style guide violations.
5. Post review comments on the PR.
```
The top section is metadata: a name and a description. The bottom is instructions the AI follows step by step. That is the entire format.
The AI reads the description to decide when to use it. When a skill matches what you asked for, it loads the full instructions. When nothing matches, it handles your request normally. You can also call a skill directly by name.
## What a plugin looks like
A plugin wraps skills and other components into one installable package. It has a manifest file (`plugin.json`) with a name, version, and description.
Beyond skills, a plugin can include:
- **Agents**: Specialized AI assistants tuned for specific jobs
- **Hooks**: Automated actions triggered by events (like running a linter after every edit)
- **MCP servers**: Connections to external tools like Slack, Jira, or a database
- **Commands**: Custom slash commands that kick off workflows
You install a plugin with a single command. Everything inside it, including the external tool connections, comes with it. No separate setup.
## When to use a skill vs a plugin
**Use a skill** when you have one repeatable workflow. Deploying to staging. Reviewing a PR. Prepping for a sales call. Writing a status update in a specific format. If the task is self-contained and the instructions fit in one file, a skill is enough.
**Use a plugin** when you have a collection of related skills that should travel together, or when the workflow needs external tool connections. A "sales enablement" plugin might bundle skills for call prep, account research, and deal analysis, plus an MCP connection to your CRM. The plugin keeps all of that packaged and versioned as one thing.
**Use neither** when the task is genuinely one-off. Not everything needs to be a skill. If you are only going to do it once, just ask the AI directly.
## The format is universal
This is the part worth knowing. Almost every major AI tool adopted the same `SKILL.md` format.
[Claude Code](https://code.claude.com) (Anthropic), [Codex CLI](https://developers.openai.com/codex) (OpenAI), [Gemini CLI](https://geminicli.com) (Google), [GitHub Copilot](https://github.com/features/copilot), [Cursor](https://cursor.com), and [Windsurf](https://windsurf.com) all read the same files. Write a skill once and it works across all of them.
Anthropic released the [Agent Skills specification](https://agentskills.io) as an open standard in December 2025. OpenAI and Google adopted it shortly after. All three co-founded the [Agentic AI Foundation](https://www.linuxfoundation.org/press/linux-foundation-announces-the-formation-of-the-agentic-ai-foundation) under the Linux Foundation to govern the standard. Over 30 tools support it now.
**The reason it spread fast is that skills are just markdown.** No binary format, no compilation, no runtime. The barrier to adoption is zero.
Some tools that do not support the shared format (Amazon Q, JetBrains AI, Aider, Continue.dev) have their own customization systems, but those are siloed. You cannot take them across providers.
## How companies distribute them
Every provider supports a similar pattern for pushing skills and plugins to an organization.
An admin creates a central repository (usually on GitHub) with a list of approved plugins. Employees get prompted to install them when they open a project. Admins control what gets installed: available for self-service, installed by default, required, or hidden for staging.
Admins can also lock down which sources employees are allowed to install from. This matters because **[12-20% of skills on at least one public marketplace were found to be malicious](https://snyk.io/blog/toxicskills-malicious-ai-agent-skills-clawhub/)** in security audits. I wrote more about [the broader AI agent security landscape](/blog/ai-agent-security) separately.
The governance model across all providers is the same: anyone can create a skill locally, sharing goes through version control, and org-wide deployment requires admin privileges. Low friction to experiment. Controlled friction to distribute.
## How skills connect to external tools
Skills tell the AI what to do. But a skill that says "post the result to Slack" needs a way to actually reach Slack.
There are a few ways to wire that up. Direct API calls work if your skill includes a script that hits an endpoint. Some plugins bundle custom tool integrations that call APIs directly. But the approach gaining the most traction is [MCP](https://modelcontextprotocol.io) (Model Context Protocol), an open standard for connecting AI tools to external services. Every major AI tool supports it now, and MCP servers can be bundled inside plugins so they install automatically.
MCP is not the only option, but it is becoming the default because it is standardized. You write the connection once and it works across providers, rather than building separate integrations for each tool.
## The security side
Three numbers worth knowing:
- **12-20%** of skills on [ClawHub](https://openclaw.com) (a public marketplace) were [found to be malicious](https://snyk.io/blog/toxicskills-malicious-ai-agent-skills-clawhub/)
- **1 in 8** enterprise security incidents now involve an AI agent system ([CrowdStrike 2025](https://www.crowdstrike.com/en-us/global-threat-report/))
- **78%** of compromised agents had broader permissions than they needed
The [OWASP Foundation](https://genai.owasp.org/resource/owasp-top-10-for-agentic-applications-for-2026/) published a top 10 for AI agent security. The top threats: goal hijacking, tool misuse, over-permissioned agents, supply chain attacks through malicious plugins, and unexpected code execution.
The practical version: install skills from trusted sources only, keep permissions tight, review skills like you review code, and pin your versions.
## Where this is going
Only [20% of companies](https://www.deloitte.com/us/en/what-we-do/capabilities/applied-artificial-intelligence/content/state-of-ai-in-the-enterprise.html) have a mature governance model for AI agents. The skills ecosystem went from nothing to hundreds of thousands of indexed skills in under four months. Over 30 products adopted the same format in the same period. 60,000+ GitHub repos use the cross-tool AGENTS.md instruction standard.
**The companies that figure out how to create, share, and govern skills are going to move faster than those still asking every person to write their own prompts.** The format is markdown. The barrier is low. The hardest part is identifying which workflows are worth standardizing, and the people doing the work already know the answer to that.
---
### The Case for One Company Harness (Not More Agents)
- Published: 2026-03-13
- Category: AI Agents
- Tags: AI Agents, Enterprise AI, Claude Code, Cowork, Agent Harness, Skills
- URL: https://tonykipkemboi.com/blog/one-company-harness
You do not need a new agent for every use case. You need a harness flexible enough to serve different roles and skills as the configuration layer.
#### Full Content

I spend most of my time figuring out what needs automating inside the company. Stakeholders come to me with a workflow that's slow or manual or both, and we figure out whether to build or buy. Most of the time I end up building custom agents. Internal-facing, always aimed at making employees faster and automating the boring stuff.
I started doing this late last year. Custom agents were the default for anything interesting. And for a while it made sense.
The work starts before any code gets written. I meet with the person or team that owns the workflow and have them walk me through every single thing they do manually. We turn that into a PRD including an initial eval dataset. Sounds straightforward but it never is.
People forget steps they make unconsciously because they've done it a thousand times. That context lives entirely in their head. Unless you pull it out and put it somewhere the agent can access, the agent fails. Not because the agent is bad but because it's missing pieces that nobody thought to write down.
**This is one of the silent killers of agent projects.** You can bolt on every guardrail you want but if the context isn't there the agent is guessing. Getting that knowledge transfer right is the actual hard part.
I came from the agent framework world so naturally that's where I started. But I felt the constraints almost immediately. You inherit the framework's opinions and sometimes those don't match what you need. I wrote about this shift on my [blog](/blog/agent-frameworks-getting-squeezed) if you're curious why.
I tried a couple of SDKs and APIs, landed on one that fit the deployment environment. Agent backend on a cloud platform, chat frontend as the interface, observability bolted on for tracing and evals. The whole setup was solid for what it needed to be at the time.
## Then December 2025 happened
New model capabilities dropped with Opus 4.6 and everything shifted. Reasoning and tool use got dramatically better. Then [Cowork](https://claude.ai) launched with [skills and plugins](/blog/agent-skills-and-plugins-explained). A skill is a single recipe for the model to execute a given workflow. A plugin is the cookbook: a collection of recipes you pull from depending on what you need.
That changed the math on everything I'd already built. The custom agents were rigid and slow to ship new features. Meanwhile the prompts, workflows, and data transformations I'd already written could be packaged as skills and suddenly scale in ways the custom agent couldn't.
## The pivot
Most of what lived inside my custom agents could be converted into skills. The prompts, the output logic, even custom scripts, all expressible as a skill or bundled into a plugin. [MCP](https://modelcontextprotocol.io) connectors let me bolt on new capabilities on demand without rewriting any code. Slack messages now send directly from the Claude harness, instead of needing a one-off integration.
I can also set up scheduled tasks once and have them run on a regular cadence as long as my laptop stays on. It's not the most efficient setup, but it works for now. **Every custom integration I create is something I'm on the hook to maintain indefinitely.** Skills and plugins move that maintenance burden onto the platform instead.
## The observability tradeoff
On a custom agent, debugging a workflow, for example a bad sales forecast, means pulling a full trace, stepping through all the tool calls, and hunting for the one prompt or retrieval that went sideways.
On Cowork, the same person tweaks the skill prompt, reruns it on a handful of deals, and sees within minutes whether the numbers finally match their spreadsheet. That's a great trade for content, ops, and reporting workflows but it's a bad one for payments, compliance reviews, or anything you may need to audit in detail later.
## This isn't for everyone
What I'm describing does not apply to every organization, industry, or use case. If your company already has the license and native connectors, teams like sales and marketing can build playbooks as skills and start moving faster immediately.
But regulated industries, strict data residency, compliance-heavy environments: those aren't migrating to Cowork and calling it a day. Custom agents still make sense when the workflow needs deep proprietary integration, when you need granular control over every agent decision, or when audit requirements demand full stack ownership. What's changed is the bar.
**The default should now be to ask whether an agent skill can handle it first.**
## Case for the harness
[Claude Code](https://code.claude.com) started as a developer tool. Terminal-based, built for engineers. [A harness, not a framework](/blog/agent-frameworks-vs-harnesses). But people used it for things well beyond coding. Anthropic saw that and built a new harness, Cowork, for the non-developers who don't want a terminal. Same model. Different harness. Different audience.
That's the mental model. **You don't need a new agent for every use case. You need a harness flexible enough to serve different roles** and robust enough to support skills, plugins, scheduled tasks, and whatever comes next. The harness is the product. Skills and plugins are the configuration layer.
The harness should get smaller over time. As models improve, things currently in the harness get trained into the model itself. So, theoretically, your harness code should be shrinking as more capable models are released.
Prompts get shorter. Custom tools get replaced by native capabilities. The harness compresses toward the minimum viable wrapper around whatever the model can't yet do on its own. A company-owned harness also serves as a backup. It can swap models if a provider goes down. No single provider should be a single point of failure.
## The people topic
There are too many platforms. Every new tool is another tab, another login. Even for me it's a lot. The adoption unlock is bringing the workflow to where people already are (for example [Slack](https://slack.com)) rather than guiding them to yet another interface. Friction kills adoption.
This is another argument for the single harness. One interface. The harness routes to the right skills and data behind the scenes. The user doesn't need to know which model is running or which plugin is active. They describe what they need and the harness figures it out.
Everything here is a point-in-time view and a snapshot in time. Most of the specific tooling will look different in a few months. That's the job right now.
You build while the ground moves and stay ready to throw things away when something better shows up.
---
### Agent Frameworks Are Getting Squeezed
- Published: 2026-03-02
- Category: Industry Insights
- Tags: AI Agents, Agent Frameworks, Enterprise AI, Automation, AI Infrastructure
- URL: https://tonykipkemboi.com/blog/agent-frameworks-getting-squeezed
Agent frameworks emerged in the gap between when models got good enough and when infrastructure caught up. That gap is closing from both directions.
#### Full Content
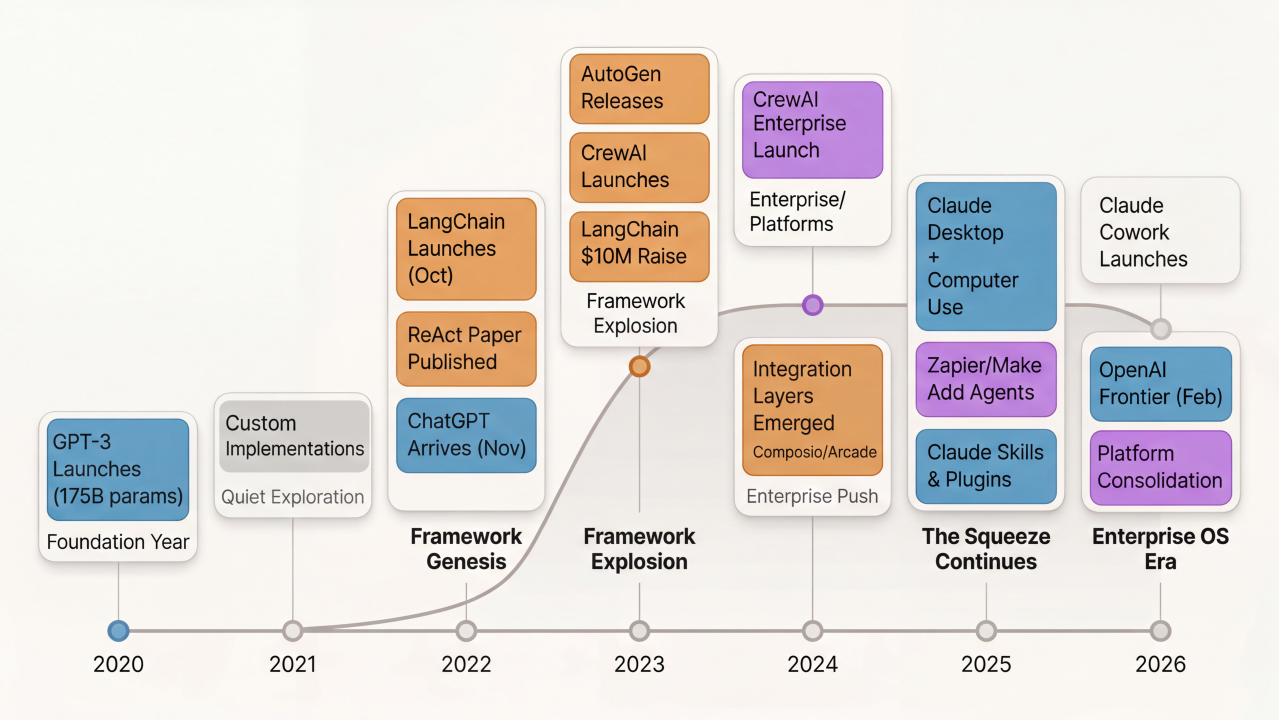
When you look at what most agent frameworks actually do, it's workflow orchestration. You define tasks, chain them together, route data between steps, add conditional logic, call external APIs. The core mechanics look familiar because we've been doing this with automation platforms for over a decade.
Agent frameworks emerged in 2023 when models became capable enough to reliably use tools and reason through multi-step tasks. They were built around LLMs and reasoning as first-class primitives. Automation platforms like [Zapier](https://zapier.com) and [Make](https://www.make.com) had been built around apps and triggers since the early 2010s. Both solve the same fundamental problem: coordinating work across multiple systems.
For about two years, agent frameworks had a clear opening. Models were good enough to be useful, but the existing automation platforms hadn't adapted yet. Frameworks like [LangChain](https://www.langchain.com), [AutoGen](https://github.com/microsoft/autogen), [CrewAI](https://www.crewai.com), and others filled that gap with developer-friendly tools for building agentic workflows.
By mid 2025 and into 2026, something happened. The market started closing in from both directions.
## From Above: AI Labs
More capable models have been released and products like [Claude Desktop](https://claude.ai) ships with Computer Use and multiple connectors. With something like Claude Cowork, you can connect to your data sources, spin up sub-agents for specific tasks, schedule tasks, and orchestrate everything from one command center. It runs on your desktop. The model, the orchestration, and the integrations all come from one place.
[OpenAI](https://openai.com) is building similar capabilities and probably more with the recent acqui-hire of [OpenClaw](https://openclaw.com) founder. So is [Google with Gemini](https://gemini.google.com). **The AI labs aren't just providing models anymore. They're providing the entire agent runtime.**
For enterprises, this matters. Most are already paying for these services. They have licenses for their employees to use Claude or OpenAI or Gemini and most instances all of them are provisioned. Why layer in a separate orchestration framework when the lab that built the model also built the agent infrastructure? The integration is tighter. The debugging is easier. The responsibility is clearer. And there's no additional vendor to manage or budget line to justify.
The decision point is becoming harder to justify. Why add another framework to do something the existing tooling already handles? That cost conversation gets difficult fast, especially in enterprises where every new tool needs security review, procurement approval, and ongoing maintenance.
Then came plugins and skills. Claude launched [agent skills and plugins](/blog/agent-skills-and-plugins-explained) that let organizations build and share domain-specific capabilities. Finance plugins. Legal plugins. Productivity plugins. You can add skills for evaluating NDAs, verifying contracts, processing specific workflows. These are shareable across the organization and built directly into the platform employees are already using.
This hit the market hard. The announcement affected valuations for vertical AI companies because, in my opinion, it changed the pricing conversation. Enterprises can now argue they can do most of what specialized tools offer using Claude. That doesn't replace those companies outright, but it compresses what they can charge. Revenue expectations shift when the baseline capability is free with an existing license.
## From Below: Automation Platforms
[Zapier](https://zapier.com) launched Agents. [Make](https://www.make.com) launched AI Agents. [UiPath](https://www.uipath.com) calls it Agentic Automation. They already had thousands of pre-built connectors, OAuth handling, permission management, and enterprise governance. They just needed to add reasoning on top.
And they did.
These platforms spent over a decade building integration infrastructure. Adding LLM-based reasoning to existing workflow orchestration is straightforward compared to building thousands of enterprise integrations from scratch.
## The Vendor Lock-In Question
The strongest case for agent frameworks is model-agnostic flexibility. Build once, swap providers with a config change. No lock-in to a single lab's ecosystem.
Recent events show why this matters. The Pentagon just designated Anthropic a supply chain risk over a dispute about autonomous weapons and surveillance guardrails. The company lost its $200 million contract, and military contractors can no longer use Claude for defense work. The situation is fluid and contained to government contracts for now, but it demonstrates the risk of platform dependence.
What happens when an enterprise decides they can't use a specific lab anymore? Policy disagreements, pricing changes, compliance requirements. If you built everything on Claude or a similar single-vendor platform, you're ripping out infrastructure. If you built on a framework with swappable model providers, you're changing a config file.
That's real value. But it's not the moat frameworks think it is.
OpenAI [launched Frontier](https://openai.com/index/introducing-openai-frontier/) in February. An enterprise platform for building and managing AI agents with integrated access to business systems, data warehouses, and internal apps. It's open to agents built outside OpenAI's ecosystem. It has governance, permissions, and compliance tooling.
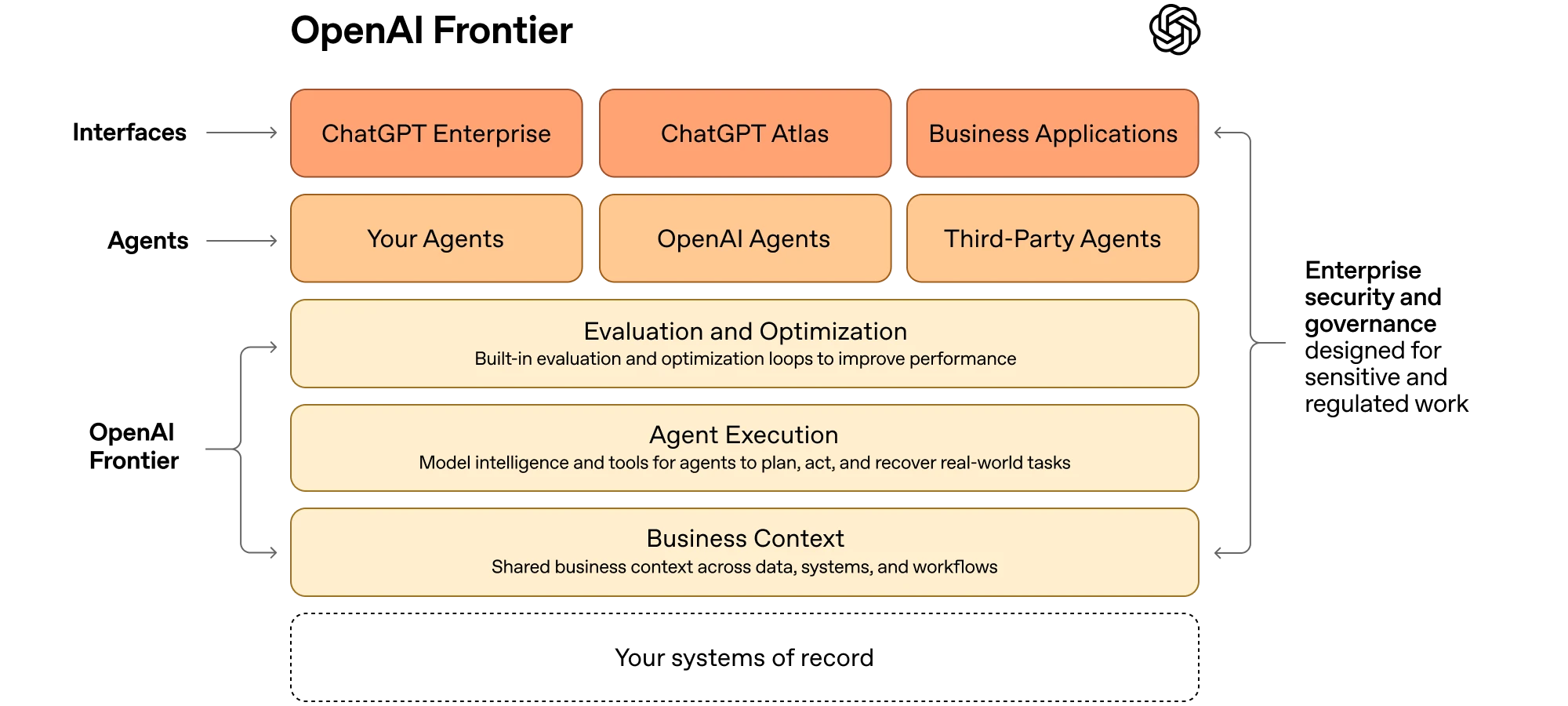
It's OpenAI's bid to become "the operating system of the enterprise." And it directly addresses the vendor lock-in concern by positioning itself as a control plane that can work across providers.
Google will build their version. Microsoft already has paths through Azure. You can bet all the big labs are working hard to capture this enterprise market. They're all building platform layers that reduce single-vendor risk while keeping you in their ecosystem.
The competition between labs actually gives enterprises options. Each lab will have different policies, different pricing, different compliance stances. That diversity is its own form of protection against lock-in. And most enterprises would rather manage relationships with two or three major labs than maintain a separate orchestration framework.
Frameworks still have a role for teams that need code-level control or specific orchestration patterns. But the vendor lock-in argument gets weaker when the labs themselves are building multi-provider management platforms. The freedom frameworks offer comes with its own dependencies on integration layers, observability tools, and ecosystem partners.
True portability requires discipline at the architecture level, not just picking the right vendor. And most enterprises will bet on the labs that own the models rather than add another layer to maintain.
## The Middle Collapses
Agent frameworks emerged in the gap between when models got good enough to be useful (2023) and when the infrastructure caught up (2025-2026). That gap is closing.
The integration disadvantage that frameworks faced in 2023 and 2024 is gone. Companies like [Composio](https://composio.dev) and [Arcade.dev](https://arcade.dev) built integration layers specifically for agents. Most frameworks now use these external tool companies for connections.
But solving integrations doesn't solve the squeeze. **AI labs are building down into orchestration. Automation platforms are building up into reasoning.** Agent frameworks are in the middle of a compression event from both sides.
Frameworks still have an architectural advantage. They were designed with agents as the default primitive from day one. The developer experience is built for agentic workflows. That matters for prototyping and experimentation.
As the underlying technology improves, architectural advantages compress. Models get better at reasoning and tool use. The abstraction layer matters less. The orchestration patterns start looking similar regardless of where they come from.
There's also a learning curve problem. Agent frameworks are opinionated. You have to learn their language, understand how they structure things, adapt to their patterns. That's friction. Compare that to going to Claude and letting it figure things out. The path of least resistance wins in enterprise adoption.
## Who Actually Uses Agent Frameworks?
Fortune 500 companies might experiment with agent frameworks. Some are using them now. But there's a shelf life to that adoption. The cost justification gets harder when AI labs and automation platforms fill the capability gaps.
The companies that stick with agent frameworks long-term are primarily consultancies. Large system integrators and boutique AI consulting firms build on these frameworks to deliver custom solutions faster than building from scratch. They white-label agentic transformation for enterprise clients, maintaining ongoing engagements through customization and integration work.
That's a real market, but it's narrower than the original total addressable market frameworks were pitching. Consultancies are intermediaries, not end customers. And they'll switch frameworks as easily as they switch any other tooling if something better comes along.
## Where Frameworks Go From Here
Historically in infrastructure, value concentrates around integration points and operational tooling, not orchestration patterns. Orchestration logic is portable. Integrations are becoming portable too. The moats frameworks thought they had are evaporating.
Agent frameworks had a moment between when models got good enough and when the infrastructure caught up. That window is closing. What's left is open source projects maintained by communities and niche tools for teams that need control over convenience.
Some will pivot to agent management services for consultancies and small shops but most will settle into being developer tools for prototyping before production deployment elsewhere. Both paths are arguably profitable, but neither is the venture-scale platform play frameworks pitched in 2023.
---
### Agent Frameworks vs Agent Harnesses
- Published: 2026-02-27
- Category: AI Agents
- Tags: AI Agents, Agent Frameworks, Developer Tools, LangChain, CrewAI
- URL: https://tonykipkemboi.com/blog/agent-frameworks-vs-harnesses
Frameworks give you building blocks. Harnesses give you a complete system. The distinction matters if you are building agents.
#### Full Content
If you've been hearing "agent framework" and "agent harness" thrown around and can't tell the difference, you're probably not alone. The terms sound interchangeable but they're not. I worked at [CrewAI](https://www.crewai.com), which is an agent framework, so I have a sense of where the boundaries are. I also wrote about [the market compression squeezing frameworks](/blog/agent-frameworks-getting-squeezed) from both directions.
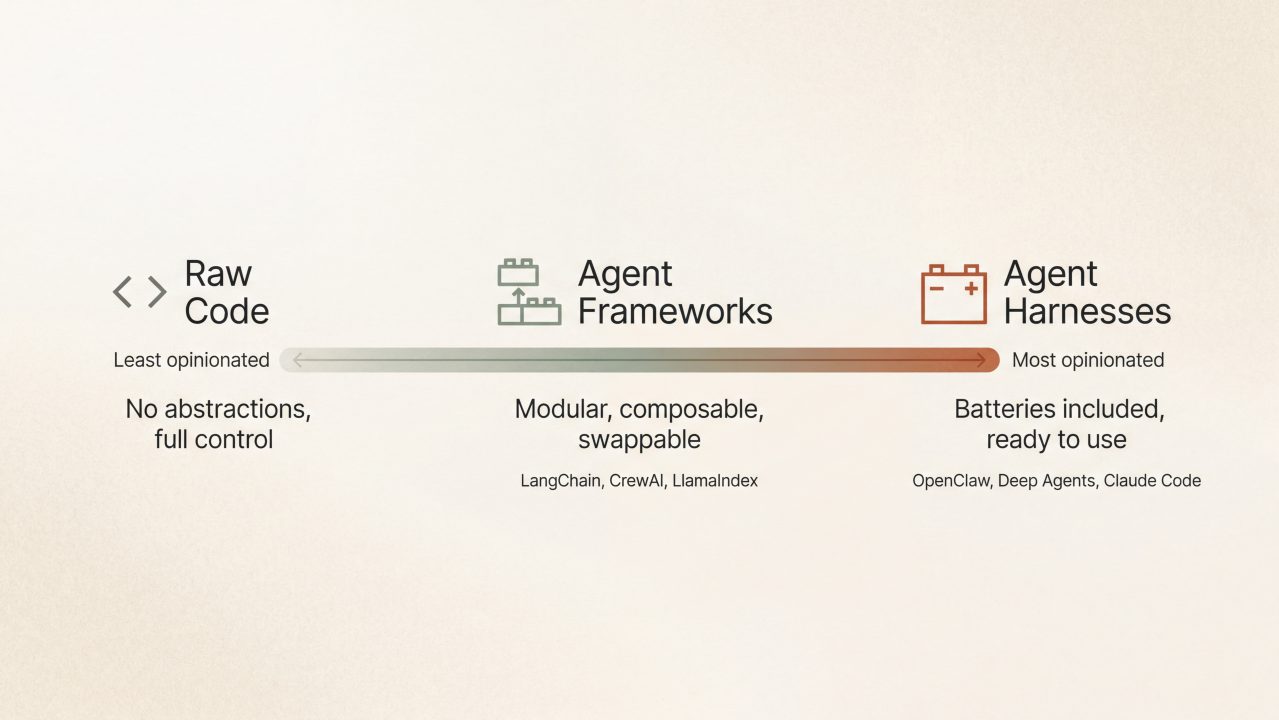
Agent frameworks and agent harnesses sit at **different points on a spectrum of opinionation**. Understanding where they sit matters if you're building agents, because it changes what you're responsible for and what the tool handles for you.
If you put agent development on a line, raw code with no abstractions sits on the far left. You're calling APIs directly, managing state yourself, building every piece from scratch. Total flexibility, total responsibility.
Agent frameworks sit in the middle. They give you structure and abstractions, but you still make a lot of decisions. You pick the memory system, you configure the tools, you define the orchestration logic. The framework has opinions about how things should connect, but it's modular. You can swap components.
Agent harnesses sit on the far right. They're maximally opinionated. Everything is baked in. You add your API keys, maybe point it at a few tools, and it runs. Memory, context management, the agent loop, safety checks. All of that is decided for you.
A framework gives you abstractions for building agents. You define roles, tasks, tools. You specify how agents coordinate, whether they work sequentially or hierarchically. The framework handles the plumbing. Calling the LLM, routing tool outputs, managing the execution loop. But you're still making architectural decisions.
The framework is opinionated about what the building blocks look like. It has a memory abstraction, a tool interface, a task structure. But those pieces are swappable. If you don't like the default memory implementation, you can plug in your own. If you want to use a different LLM provider, you configure it. The framework gives you a standard interface, but you're still composing the system.
That modularity is the point. Frameworks are built for people who want to build agents, not just use them. You're expected to understand how the pieces fit together, because you're the one deciding which pieces to use.
A harness doesn't give you building blocks. **It gives you a complete system.**
The best recent example is [OpenClaw](https://openclaw.com), which went viral a few weeks ago. It's a harness. You download it, add your API keys, and suddenly you have an agent you can chat with on WhatsApp, Telegram, and other platforms. Memory is handled. Context management is handled. The agent loop is handled. Tool calling, permissions, state persistence. All of it is built in.
You're not configuring a memory system. You're not deciding how tools get registered or how the agent recovers from errors. Those decisions were made by whoever built the harness. Your job is to point it at a task and let it run.
That's the tradeoff. You get something that works immediately, but you don't get to change how it works under the hood. The harness has an opinion about everything, and you're accepting that opinion when you use it.
The spectrum matters because it maps to different problems.
If you're prototyping, experimenting, or building something custom, you want a framework. You need the flexibility to swap components, test different approaches, and control the details. The framework gives you structure without locking you in.
If you need something that works now, reliably, for a specific use case, you want a harness. You're trading control for speed. The harness has already solved the hard problems. Context management, durable execution, error recovery. You're just using the solution.
**Frameworks are for builders. Harnesses are for users.**
That doesn't mean one is better. It means they're solving different problems. What you're solving determines which one you need. The line isn't always clean, and I'm not sure it should be.
Some frameworks are adding harness-like features. [LangChain](https://www.langchain.com) is a good example. They released [Deep Agents](https://blog.langchain.com/deep-agents/), which they explicitly call an "agent harness" that sits on top of their framework. It comes with built-in planning tools, file system access for context management, subagent spawning, and memory persistence. You're still using LangChain under the hood, but Deep Agents gives you batteries-included defaults so you don't have to wire everything together yourself.
LangChain actually [distinguishes between three layers](https://blog.langchain.com/agent-frameworks-runtimes-and-harnesses-oh-my/) in their own stack. LangChain (the original library) is the framework. [LangGraph](https://www.langchain.com/langgraph) is what they call the "agent runtime," which handles execution, state management, and durability. Deep Agents is the harness that sits on top of both. That's one company spanning the entire spectrum. Framework for composing agents, runtime for executing them reliably, harness for using them out of the box.
That's a framework company moving right on the spectrum. Deep Agents is still modular. You can swap backends, configure tools, adjust prompts. But it gives you a working system without requiring you to assemble every piece.
On the flip side, harnesses aren't as locked down as they might sound. Take [OpenClaw](https://openclaw.com). It's maximally opinionated out of the box, but if you download the source code, you can swap implementations. You can change how memory works, adjust the agent loop, modify tool handling. It's just that most people won't, because the default already works.
The distinction is about what's already decided when you start. **A harness ships with decisions baked in. A framework ships with options exposed.** If you're using a harness, you're accepting most of those decisions and configuring around the edges. If you're using a framework, you're making those decisions yourself and assembling the system.
What you're solving determines which one you need. Sometimes you need to bypass the agent frameworks entirely and build a simple [ReAct agent](https://arxiv.org/pdf/2210.03629) using the model endpoints directly. How much you want already built determines which one you pick.
---
### Be a Generalist (if you have to choose)
- Published: 2026-02-26
- Category: Career
- Tags: Career, AI Agents, Generalist, Enterprise AI
- URL: https://tonykipkemboi.com/blog/be-a-generalist
AI got really good at going deep. What it cannot do is range across domains and know which room to open. That is the generalist advantage.
#### Full Content

There's a version of career advice that has felt true for a long time.
Get deep in one thing. Become the expert. Own a vertical so completely that you become the person people call. The T-shape model, broad surface with one deep spike, has been the framework for a while now.
That advice isn't wrong. But I think the T is shifting.
AI got really good at going deep. Not at everything, and not perfectly, but direct an agent toward a specific problem with enough context and it will outpace most generalists and keep pace with many specialists. It can write the SQL, parse the research paper, draft the legal summary, generate the code. **Depth, for a lot of tasks, is becoming a commodity.**
What AI is genuinely not good at is ranging. Connecting a pattern from genomics to data engineering to agent orchestration and knowing why that matters. Holding five different mental models at once and deciding which one applies. That's not a training problem. That's a life problem. And it's one generalists have been quietly solving for years.
A generalist carries a lot of surface area. They might have a foot of understanding across a dozen domains, not deep, but real. Enough to have a conversation, ask the right question, recognize when something's off.
With AI, that foot becomes a foundation. You point the model at the vertical, give it direction, and now you're operating with something closer to depth, on demand, across all of them.
A specialist with a narrow spike is still valuable. They can verify. They can catch what the model gets wrong. That matters. But they're working in one room. The generalist is moving between rooms and knows which ones to open.
I didn't plan to be a generalist. I don't think anyone does.
I grew up in Kenya, came to the U.S. for college, joined the Army, spent years in medical labs and genomics research, taught myself Python from a book someone handed me, enrolled in a CS program at Penn, became a data engineer, then a developer advocate, and now I build agentic systems in production. None of that was a strategy. It was just following what felt interesting at each turn.
But the through line is surface area. Each of those environments gave me a different mental model. The lab gave me rigor, you don't trust output you haven't validated. The Army gave me structure, define the mission, assign the resources, execute, debrief. Growing up in a different country gave me something harder to name, a kind of distance from assumptions that most people carry without knowing it. You learn to observe a system before you assume you understand it.
All of that is what I draw on now when I'm working with AI systems. Not any single deep expertise. The range.
So the question isn't whether you should be a generalist or a specialist. Most people don't get to choose cleanly anyway. Life makes you both things at different times.
The better question is what have you already lived through that you're not counting.
The career change you made five years ago. The industry you left. The country you grew up in. The job that felt like a detour. Every one of those things changed how you see, and that's what you're actually working with now.
For a long time, the quiet anxiety of being a generalist was feeling one step away from being found out when something got hard enough. That you needed to pick a lane, go deep, stop moving around. That breadth was a liability.
That's inverting. The depth you need on any given problem is increasingly something you can get to. **The range you've built over a lifetime isn't.**
The people who are going to build the most interesting things over the next few years aren't necessarily the ones who know one domain the best. They're the ones who can hold multiple domains at once, move between them, and point the right tools at the right problems.
There's a good chance that's already who you are, and you just haven't had a reason to call it an advantage until now.
---
### Securing the AI Frontier
- Published: 2025-05-01
- Category: Security
- Tags: AI Security, AI Agents, Enterprise AI, Cybersecurity, Prompt Injection
- URL: https://tonykipkemboi.com/blog/ai-agent-security
AI agents are amplifying the need for AI security. The global AI cybersecurity market is projected to reach $135 billion by 2030.
#### Full Content

My prediction: **_"2025 is the year of AI agents but 2026 will be the year of AI security."_**
We're almost halfway through 2025 and AI agents are already in production!
The next natural evolution is security threats and reports of hacks; because
hackers love exploiting productionized products, especially new and innovative ones.
Most of the cybersecurity companies are already positioning themselves as AI security providers.
Consolidation has started and will continue for the rest of this year.
Palo Alto Networks just acquired Protect AI for over [$500 million](https://www.geekwire.com/2025/palo-alto-networks-acquires-protect-ai/),
highlighting how crucial AI security has become; if it wasn't already.
The global AI cybersecurity market is expanding dramatically—from $25 billion in 2023 to a projected
[$135 billion by 2030](https://lakera.ai/reports/security-trends-2024). Startups and established cybersecurity firms alike are attracting significant investment,
positioning themselves as essential providers of AI security solutions.
LLMs have been known to have security vulnerabilities, and AI agents are going to be no exception. In fact, AI agents just magnify the risk of these vulnerabilities.
## Unique Threats in AI Agent Security
AI agents introduce specific vulnerabilities beyond traditional cybersecurity risks:
- **Data Poisoning**: Attackers deliberately corrupt AI training datasets, resulting in incorrect or malicious outcomes.
- **Prompt Injection**: Adversaries manipulate AI inputs to bypass security controls and cause unintended disclosures.
- **Model Theft**: Proprietary AI models and critical business data risk being stolen, potentially leading to severe competitive disadvantages.
- **Tool Misuse**: Attackers can manipulate AI agents to misuse their integrated tools, potentially triggering harmful actions or exploiting vulnerabilities.
- **Credential Leakage**: Exposed service tokens or secrets can lead to impersonation, privilege escalation, or infrastructure compromise.
- **Unauthorized Code Execution**: Unsecured code interpreters in AI agents can expose systems to arbitrary code execution and unauthorized access.
These are not hypothetical risks. High-profile incidents, including [Microsoft's Bing Chat revealing sensitive internal rules](https://www.zdnet.com/article/microsofts-chatgpt-powered-bing-reveals-its-codename-and-rules-and-argues-with-users/) and [financial frauds involving deepfake technologies](https://www.fincen.gov/news/news-releases/fincen-issues-alert-fraud-schemes-involving-deepfake-media-targeting-financial),
have demonstrated the real-world impact of these threats.
## The Need for Secure AI Agents
As AI agents become more autonomous and powerful, they require specialized security approaches which involve addressing multiple layers:
- The foundation model itself
- The agent framework
- The tools and integrations
- The runtime environment
- The data being processed
Each layer presents unique challenges and requires specific security controls. I wrote a deeper dive on [how RBAC and identity management apply to agents](/blog/agent-authentication-rbac) separately.
## AI Agent Security Startups Worth Watching
**[HiddenLayer](https://hiddenlayer.com)**
- Founded: 2019
- Funding: $50M Series A (2023)
- Unique Approach: ML security platform with automated threat detection
**[Protect AI](https://protectai.com) (acquired by [Palo Alto Networks](https://paloaltonetworks.com) in 2025)**
- Founded: 2022
- Funding: $108.5M
- Unique Approach: Secures ML supply chains and DevSecOps integration
**[Robust Intelligence](https://robustintelligence.com) (acquired by [Cisco](https://cisco.com) in 2024)**
- Founded: 2019
- Funding: $53M
- Unique Approach: AI firewall and proactive model validation
**[Lakera](https://lakera.ai)**
- Founded: 2021
- Funding: $20M Series A (2024)
- Unique Approach: Real-time security for generative AI applications
**[CalypsoAI](https://calypsoai.com)**
- Founded: 2018
- Funding: $23M Series A1
- Unique Approach: Validates AI model safety and continuous monitoring
**[Adversa AI](https://adversa.ai)**
- Founded: 2019
- Funding: $8M
- Unique Approach: Focuses on adversarial robustness and protection against ML model attacks
**[Stytch](https://stytch.com)**
- Founded: 2020
- Funding: $123M (Series B in 2022)
- Unique Approach: Passwordless authentication platform enhancing security for AI applications
**Note**: This list is not exhaustive. I'm sure I missed some. Feel free to [reach out to me](https://linkedin.com/in/tonykipkemboi) if you wish to add any.
---
### RBAC for AI Agents: Identity, Permissions, and Access Control
- Published: 2025-04-15
- Category: Security
- Tags: RBAC, AI Agents, Authentication, Access Control, Identity Management, Enterprise AI
- URL: https://tonykipkemboi.com/blog/agent-authentication-rbac
As AI agents become digital workers, organizations must rethink identity, access, and permissions for non-human actors. Here's why agent authentication and fine-grained RBAC will define the next era of AI adoption.
#### Full Content

As AI agents move from proof-of-concept into production, a new set of challenges are emerging. One of them is identity and access management for these non-human actors.
Today, every employee at a company gets a user profile, a set of credentials, and carefully scoped permissions—often managed by sophisticated RBAC (role-based access control) systems. But what about the AI agents that are now reading your emails, updating your CRM, or querying your database?
If agents are to become true digital workers, they'll need to be treated like employees: with profiles, audit trails, and—critically—permissions. Otherwise, we risk creating a shadow workforce with no accountability, no oversight, and massive [security risks](/blog/ai-agent-security).
## Why Agent Identity Matters
Agents increasingly act on behalf of users, teams, or entire organizations. If agents are **_anonymous_** or **_over-permissioned_**, they become a new vector for data leaks, fraud, and compliance failures. Just as with human employees, we need to know: who did what, when, and why?
TL;DR, these are the reasons why agent identity and access management are critical:
- **Audit Trails:** Every agent action should be traceable.
- **Accountability:** Agents must operate within clear boundaries.
- **Compliance:** Regulations may soon require agent identity management.
## Agent Profiles: The New User Accounts
Think of an AI agent profile as a digital employee file:
- **Unique Agent Identifier:** How the agent is recognized in the system
- **Credentials** (API keys, OAuth tokens, etc.): What the agent uses to authenticate to services
- **Capabilities:** What the agent is allowed to do
- **Owner/Supervisor:** Who created or manages the agent
- **Context:** Purpose, current task, environment
Agent profiles will enable better management, trust, and lifecycle control (onboarding, offboarding, suspension).
## RBAC for Agents: Roles, Permissions, and Fine-Grained Access
Assigning roles and permissions to agents is not going to be a nice-to-have—it will be a necessity. But the bar is even higher than for humans:
- **Least Privilege:** Agents should only access what's absolutely necessary.
- **Dynamic Permissions:** As agents learn or change roles, their access must update in real time.
- **Revocation:** Removing agent access instantly is critical for security.
### Fine-Grained Data Access: Beyond the Row, Down to the Cell
In many organizations, access controls are not just at the file or table level—they're at the row or even cell level. For example, a sales agent may only see revenue data for their region, or a healthcare agent may see only certain fields in a patient record.
AI agents will need to respect these boundaries:
- **Cell-Level RBAC:** Agents should only read/write the specific data they're authorized for.
- **Context-Aware Policies:** Access rights may depend on the agent's task, user, or even time of day.
- **Auditability:** Every access—especially to sensitive data—must be logged and reviewable.
## The Opportunity: Building the Agent Identity Layer
Just as Okta and Auth0 built massive businesses around human identity, there's a coming wave of startups building identity, RBAC, and lifecycle management for agents. We'll see:
- Agent directories (who are the agents in my org?)
- Permission dashboards
- Automated onboarding/offboarding
- Delegation and escalation workflows
## Challenges and Open Questions
- How do you revoke agent access instantly, everywhere?
- How do you handle agent-to-agent delegation and impersonation?
- What about agents that spawn other agents—who is responsible for their actions?
- How do you ensure explainability and transparency as agents become more autonomous?
## Other Open Questions
- **User Consent:** How do users grant (and revoke) agents permission to act on their behalf?
- **Agent Lifecycle:** What happens to access and data when an agent is retired or replaced?
- **Cross-Org Collaboration:** How are permissions managed when agents work across company or department boundaries?
- **Human-in-the-Loop:** When should humans be able to override or audit agent actions in real time?
- **Privacy:** How do we ensure agents only access the minimum data needed, especially with sensitive info?
- **Impersonation Risks:** How do we prevent fake or hijacked agents?
- **Regulation:** How will new laws and liability shape agent identity and access?
These are just a few of the interesting topics that will shape how we trust and deploy AI agents at scale. We've already dealt with these issues in the human world, and the same principles will apply to agents, but with even more complexity.
## Conclusion
As organizations deploy more AI agents, the need for clear identity and access controls will only grow. The best solutions will balance security, flexibility, and transparency—without getting in the way of what makes agents powerful in the first place.
---
### SaaS Isn't Dying—It's Becoming the Toolbox for AI Agents
- Published: 2025-02-02
- Category: Industry Insights
- Tags: SaaS, AI Agents, Automation, Enterprise AI, API Design
- URL: https://tonykipkemboi.com/blog/saas-vs-agents
SaaS isn't disappearing—it's evolving into the backend infrastructure that AI agents use to get work done.
#### Full Content

There's been a lot of talk about AI agents *killing* SaaS.
This is not entirely true in my opinion.
SaaS isn't disappearing—it's evolving into **the backend infrastructure that AI agents use to get work done**.
The real shift isn't about replacing software. It's about **who (or what) is using it**.
Right now, humans are the primary users of SaaS tools.
Soon, **AI agents will be the primary users**—handling workflows autonomously while humans focus on strategy.
But here's the thing: **AI agents don't work without SaaS**. They need software to connect to, APIs to call, and data to pull from.
## AI Agents Aren't Replacing SaaS, They're Becoming the New Users
Let's talk about what this actually means.
Today, a salesperson logs into:
- HubSpot to check leads
- LinkedIn to send DMs
- Gmail to follow up
- Notion to take notes
Soon, an AI sales agent will do all of that:
- Monitor CRM activity
- Draft and send follow-up emails
- Auto-update deal statuses
- Schedule meetings in Calendly
But does that mean HubSpot is dead? Nope.
It just means the user is no longer a human clicking buttons—it's an AI agent making API calls.
The same pattern will play out across **every industry**.
## Marketing: No More Clicking Around in CRMs
Today:
- Marketers log into HubSpot, Salesforce, or Mailchimp to launch campaigns.
- They analyze performance, tweak copy, and optimize manually.
Soon:
- An AI agent will auto-adjust campaigns based on real-time data.
- It will rewrite ad copy dynamically, adjust budgets, and refine targeting *without human intervention*.
But what is it using? **The same SaaS tools—just better**.
HubSpot doesn't die—it just becomes **an invisible engine powering AI-driven marketing**.
## HR & Recruiting: AI Agents Will be Hiring for You
Right now, recruiters:
- Manually post jobs, screen resumes, and email candidates.
- Waste hours scheduling interviews.
Soon, an AI hiring agent will:
- Auto-post jobs based on hiring needs.
- Analyze resumes before a human ever sees them.
- Send outreach emails and schedule interviews dynamically.
Does that mean Workday, Lever, or Greenhouse are obsolete? No.
They just become **tools that AI agents use to recruit at scale**.
## Finance & Ops: AI Agents Will Run Your Books
CFO workflows today:
- Checking QuickBooks, Stripe, and Expensify for financial insights.
- Approving expenses and running forecasts manually.
Soon, AI-powered CFO agents will:
- Pull financial reports automatically.
- Flag unusual transactions for review.
- Predict cash flow trends and recommend cost-saving moves.
But they're not doing this in a vacuum—they're still calling on **QuickBooks, Expensify, and Tableau**.
The difference? **No human is clicking through dashboards anymore**.
## Now, What if AI Agents Build Their Own SaaS?
What if AI agents start building their own SaaS—then other AI agents consume that software on behalf of users?
The AI agents will be working in **crews**, much like departments in an organization:
- One group of AI agents could develop and maintain a customer relationship platform.
- Another crew might build a content management system for marketing.
- Yet another team could create specialized analytics tools.
In this scenario, **AI agents create, integrate, and consume SaaS tools in a fully autonomous cycle**. The hierarchy might mirror modern org structures, with different AI **"departments"** handling specific tasks.
This evolution doesn't spell the end of SaaS. It just means that the very fabric of SaaS will be woven by AI.
- Even if AI agents build their own tools, the underlying model is the same: **modular, API-driven services**.
- SaaS products will still be the building blocks, only now they'll be crafted and orchestrated entirely by AI agents.
Whether built by humans or AI, these tools must deliver robust, specialized capabilities that are hard to replicate in-house. The value remains in the quality, security, and efficiency of the software—qualities that make these tools indispensable.
So, while the players might change, the game stays the same: if your platform isn't built for AI-driven integration and autonomous operation, you're falling behind TBH.
## The Future of SaaS is Invisible
The biggest SaaS brands of the next decade will be **the ones you don't even log into**.
AI agents will interact with them so seamlessly that they'll disappear into the background.
UI will be a thing of the past as AI agents will be able to interact with your software in natural language and not through a UI.
This is the shift: SaaS isn't going away. It's just becoming the infrastructure behind AI-driven work.
So what should SaaS companies do now?
- Prioritize API-first design – make it easy for AI agents to use your product.
- Build automation-first features – AI agents will be your next big user base.
- Move beyond UI-driven workflows – the future isn't dashboards, it's direct integrations.
The question isn't *"Will AI kill SaaS?"*
The real question is: **Is your SaaS ready for AI to be its biggest customer?**
---
### You're Leading the AI Revolution
- Published: 2025-01-22
- Category: Industry Insights
- Tags: Consumer AI, AI Agents, Enterprise AI, AI Adoption, Technology Trends
- URL: https://tonykipkemboi.com/blog/consumers-leading-ai-revolution
Discover how consumers are outpacing enterprises in AI adoption and why this shift is redefining the future of technology.
#### Full Content

AI is everywhere right now. If you've ever asked ChatGPT a random question or played around with a fun avatar generator, congratulations—you're part of the AI revolution and you're leading the charge in AI adoption.
What's wild is this: consumers (that's you and me) are outpacing enterprises when it comes to jumping on the AI train. That's a complete flip from most other tech cycles. Usually, the big corporations figure things out first, and we eventually get integrated as part of a product offering.
So, why's it different this time? Here's my take:
#### 1. AI is Ridiculously Accessible
You don't need a PhD, a fat wallet, or some corporate information technology team to get started with AI. Platforms like ChatGPT, Midjourney, and CrewAI are just... there. Free trials, low-cost plans, and easy interfaces mean you can start playing with AI in minutes.
#### 2. We're Selfish (in the Best Way)
AI tools solve our everyday problems **right now**. Need a workout plan? Ask ChatGPT. Struggling with meal ideas? Ask Claude. Want a cool birthday card design? Use Midjourney or Replicate to generate an image. Want to automate a list of complex tasks? Use CrewAI.
Consumers are using AI for fun, creativity, and productivity, while enterprises are still figuring out how it fits into their big-picture strategies.
#### 3. Most Contagious Thing Since 'Baby Shark'
AI-generated stuff is *everywhere*. Your friend's new profile pic, a viral tweet, or even that hilarious AI-written song—it's all over social media. People see it, think "I want to try that," and boom—another new user.
#### 4. Businesses are Stuck in Their Own Red Tape
Big companies have way more to think about: compliance, integrating AI into old systems, and making sure customer data isn't leaked everywhere. For the rest of us? We just care if it works.
This is not a negative per se as there are industries that need tighter regulations around AI, such as healthcare, finance, and military.
#### 5. Cost-Effective for Individuals
Most AI tools have free plans or cost less than your coffee habit. For enterprises, scaling these tools means bigger costs, more negotiations, and longer approval processes.
#### 6. Consumer-First Innovation
In past tech cycles, innovation was usually built for companies first. Think about early computers or software—businesses got the shiny new toys, and consumers had to wait. With AI, it's flipped. Companies like OpenAI and Meta are focusing on consumer consumption more.
## So What Does This Mean?
We are driving AI innovation right now. We're the beta testers, the explorers, and the ones pushing these tools into the spotlight. Enterprises will catch up (they always do), but for now, the playground belongs to us.
Enjoy it. Create. Experiment. And keep leading the way.
---
### Get Started with AI Agents Using CrewAI
- Published: 2024-12-12
- Category: Tutorials
- Tags: AI Agents, CrewAI, LLMs, Automation, Tutorial
- URL: https://tonykipkemboi.com/blog/crewai-quickstart
Learn how to build your first AI agent using CrewAI, a framework for creating autonomous AI agents that can work together to accomplish complex tasks.
#### Full Content

As a developer advocate at [CrewAI](https://crewai.com), I get asked a lot about how to get started with building AI agents.
In this brief blog post, I'll walk you through the process of getting started with CrewAI and creating your first AI agent.
## What is CrewAI?
CrewAI is an innovative framework designed to orchestrate role-playing AI agents. It allows you to create autonomous AI agents that can:
- Work together in a hierarchical structure
- Share context and information
- Execute complex tasks sequentially or in parallel
- Integrate with various LLM providers
## Setting Up Your Environment
First, you'll need to install CrewAI and CrewAI tools:
```bash
pip install crewai crewai-tools
```
You'll also need to configure your LLM provider. CrewAI supports various options including:
- OpenAI
- Anthropic
- Local models via Ollama
- Google Vertex AI
- Azure OpenAI
- [More here](https://docs.crewai.com/concepts/llms#provider-configuration-examples)
## Creating Your First Agent
There are [various ways](https://docs.crewai.com/concepts/agents) to create an agent, but I'll show you how to create a simple agent in CrewAI.
First, configure your API keys:
```bash
# Get your free API key here: https://serper.dev
export SERPER_API_KEY='your_serper_api_key'
```
Then create a file called **"main.py"** and add the following code:
```python
from crewai import Agent, Task, Crew, Process, LLM
from crewai.tools import SerperDevTool
# Create an LLM provider
llm = LLM(
model='o1-preview',
api_key='your_openai_api_key',
temperature=0.7
)
# Create a research agent
researcher = Agent(
role='Research Analyst',
goal='Conduct detailed research on AI technology trends',
backstory="""You are an expert research analyst with a focus on AI technology.
You have a track record of identifying emerging trends and providing actionable insights.""",
tools=[SerperDevTool()],
llm=llm,
verbose=True
)
```
## Defining Tasks
Tasks are what agents need to accomplish:
```python
# Create a task
research_task = Task(
description="""Analyze the latest developments in AI agents and autonomous systems.
Focus on real-world applications and emerging trends.""",
expected_output="An executive summary of comprehensive insights into the current state of AI agent technology",
agent=researcher,
)
```
## Assembling Your Crew
Now let's put it all together:
```python
# Create the crew with our agents and tasks
crew = Crew(
agents=[researcher],
tasks=[research_task],
process=Process.sequential,
verbose=True
)
# Kick off the work
result = crew.kickoff()
```
Run your code with the following command:
```bash
python main.py
```
## What Did We Just Do?
That's it! You've successfully created your first AI agent using CrewAI. You should see a full report of your task in the terminal.
You can further customize your agents, tasks, and crew as needed and add more complex workflows.
Another thing to note is that you can use Pydantic models to make sure you get consistent task outputs and agent responses. Watch this [tutorial](https://www.youtube.com/watch?v=dNpKQk5uxHw) for more details on how to use Pydantic models with CrewAI.
## Best Practices to Keep in Mind When Building with CrewAI
1. Give agents clear, specific roles and goals
2. Provide relevant context in task descriptions
3. Use appropriate tools for the task
4. Not all LLMs are created equal; for example, some are not suitable for tool calling
5. Use Pydantic models to ensure consistent task outputs and agent responses
Check out CrewAI [documentation](https://docs.crewai.com/) for more detailed information and advanced usage examples.
**PS**: _I manage the docs for CrewAI. If you have any questions or feedback, don't hesitate to reach out to me on [Twitter](https://twitter.com/tonykipkemboi)._
---
## End of Document
This document was automatically generated and contains the full content of tonykipkemboi.com for AI/LLM consumption.
Last updated: 2026-04-18T05:06:31.947Z