
I built Rekody — a CLI dictation tool, kind of a Wispr Flow for the terminal. The day I tried dictating in my first language, Whisper had no idea what to do with me. So I taught it — for the cost of a steak dinner.
Kalenjin is spoken by roughly 6 million people in Kenya. It's my first language. It's also not one of the 99 languages OpenAI's Whisper was trained on. Feed a Kalenjin recording to Whisper and you get confident nonsense: phonetic mush, repetition loops, occasionally words with Icelandic diacritics.
That's the practical problem. Voice interfaces, captioning, accessibility tools, transcription for archives and oral histories — they all quietly exclude anyone who speaks outside the 99. Usually the fix requires either a big lab to add your language to their next release, or training a new model from scratch. Neither is accessible to an individual.
There's a third option, which is the subject of this post: train a small adapter on top of the existing model. Retraining Whisper from scratch would mean weeks on a GPU cluster for 809M parameters. LoRA (Low-Rank Adaptation) adds a few million trainable parameters on top of a frozen base model. Think of it like a sticky note on a textbook: the textbook stays the same, the sticky note teaches the reader the new thing it needs to know for this specific page. A few million parameters, a few hours on a rented GPU, a few dollars. You end up with a model that handles your language and still handles everything the base model already knew.
Here's how that went for Kalenjin, end to end. Budget target: ~$24. Weekend. Solo.
A quick glossary before we dive in. Read these once, then follow along.
Link to WER — Word Error RateWER — Word Error Rate
The percentage of words a model gets wrong. Measured as the number of word-level edits (substitutions + deletions + insertions) needed to turn the model's output into the reference transcript, divided by the reference word count.
- 0% = perfect. Every word matches.
- 100% = every word is wrong or missing.
- Over 100% happens when the model invents extra words the reference didn't have. An untrained model hallucinating
njia njiawe ndo njiawe ndo njiawe ndo...for 50 repetitions can easily produce 200-500% WER.
WER counts whole words. One letter wrong = the whole word is wrong. One extra space splitting a word in two = two errors.
Link to CER — Character Error RateCER — Character Error Rate
The same calculation as WER but at the character level. Edit distance of characters, divided by reference character count.
- 0% = every character matches.
- 100% = every character is wrong.
Link to Why both, with Kalenjin examplesWhy both, with Kalenjin examples
For English, WER and CER usually track each other. For Kalenjin — agglutinative, with inconsistent orthographic conventions — they diverge sharply. Three real examples from our eval data:
Example 1 — word-boundary split.
ChopchinkeeChopchin geiThe model heard the right sound but dropped a space in a different place. To a Kalenjin speaker listening back, these are the same. To WER, this is 100% error (one reference word, two "wrong" predicted words). To CER, 8 of the 11 characters match — about 25% error.
Example 2 — orthographic variant.
ngokenikngogenikOne letter different (k vs g). Sounds identical to a native ear; both spellings appear in Kalenjin writing. WER counts this as 100% wrong. CER counts it as 1 character off in 8 — about 12.5%.
Example 3 — proper noun.
BosniaOsiniaThe model heard the phonemes but chose a different spelling. WER: 100%. CER: 2 characters off in 6 — about 33%.
Across hundreds of clips, small orthographic mismatches add up to a WER floor we can't cross, even on predictions a native reader would call correct. CER floats below that floor and tracks closer to what a human ear perceives. For African agglutinative languages specifically, published work (Ali & Renals; "Advocating CER" 2024) finds CER correlates ~5 points better with human judgment than WER.
I still report WER because every ASR paper does and readers want comparable numbers. CER is the one I'd pick if I only got one.
Link to CoverageCoverage
A metric I ended up introducing after discovering that the model was transcribing only half the audio and WER didn't flag it.
coverage = predicted_word_count / reference_word_count
1.0= the model produced roughly as many words as the reference expected< 0.6= severe truncation (model gave up early)> 1.4= over-generating (usually a repetition loop)
Coverage doesn't measure quality. It measures how much the model said. Paired with CER it's a much better diagnostic than WER alone. WER catches "wrong half" but misses "missing half" — coverage catches missing-half in one number.
Link to Base model, adapter, shardBase model, adapter, shard
- Base model: The pre-trained Whisper checkpoint I started from. Weights are frozen during my training.
- Adapter: The small set of new weights LoRA learns on top of the base. Stored as a ~50 MB file. At inference, base + adapter = Kalenjin-specialized model.
- Shard: A single parquet file containing a few thousand audio clips plus transcripts. Anv-ke/Kalenjin is 204 shards, ~450 hours of audio.
Link to Reproducibility — the canonical recipe + metrics fileReproducibility — the canonical recipe + metrics file
Every WER/CER/coverage number in the verdict and the comparison tables is reproduced under one consistent recipe so they're directly comparable. The recipe and the source-of-truth file:
Recipe (chunked + beam=5, the recommended decoding setup):
generate_kwargs = dict(
language="sw", task="transcribe",
num_beams=5,
chunk_length_s=30, stride_length_s=(5, 5),
return_timestamps=True,
compression_ratio_threshold=1.35,
no_repeat_ngram_size=3,
repetition_penalty=1.15,
temperature=(0.0, 0.2, 0.4, 0.6, 0.8, 1.0),
)Normalization (applied identically to refs and predictions before scoring):
- lowercase
- replace
[cs]with space (preserves the inner code-switched word) - drop
[pause],[sigh],[laugh],[breath],[noise],[silence] - strip standalone punctuation
.,;:?!"/\\ - collapse whitespace
Source of truth: canonical_metrics.json. Every number in the verdict table and the dialect tables is reproduced from this single file. The code that computes it lives at audit_recompute.py.
If a number elsewhere in the post differs, it's a story-beat number — i.e., what the eval said at an earlier point in the project under a different recipe. Those tables are explicitly labeled with their recipe (G-seq, G-chunk, or B5-chunk).
Link to Story beatsStory beats
Link to Day zeroDay zero
- MacBook Air M2, 16 GB RAM. Fine for data exploration, not for training.
- Compute: Modal with $30 in starter credits, A10G GPU at $1.10/hr. Budget target: ~$24 total.
- Model:
openai/whisper-large-v3-turbo. 809M params, 4-layer decoder. The turbo variant trades a little accuracy for roughly 6x inference speed. - Dataset:
Anv-ke/Kalenjin, curated by the African Next Voices team in Kenya. Gated on HuggingFace; access request had been pending a week. Got approved on 2026-04-22. 143.86 GB of audio and transcripts. This project literally does not happen without their work. Full acknowledgements below.
Link to The dataThe data
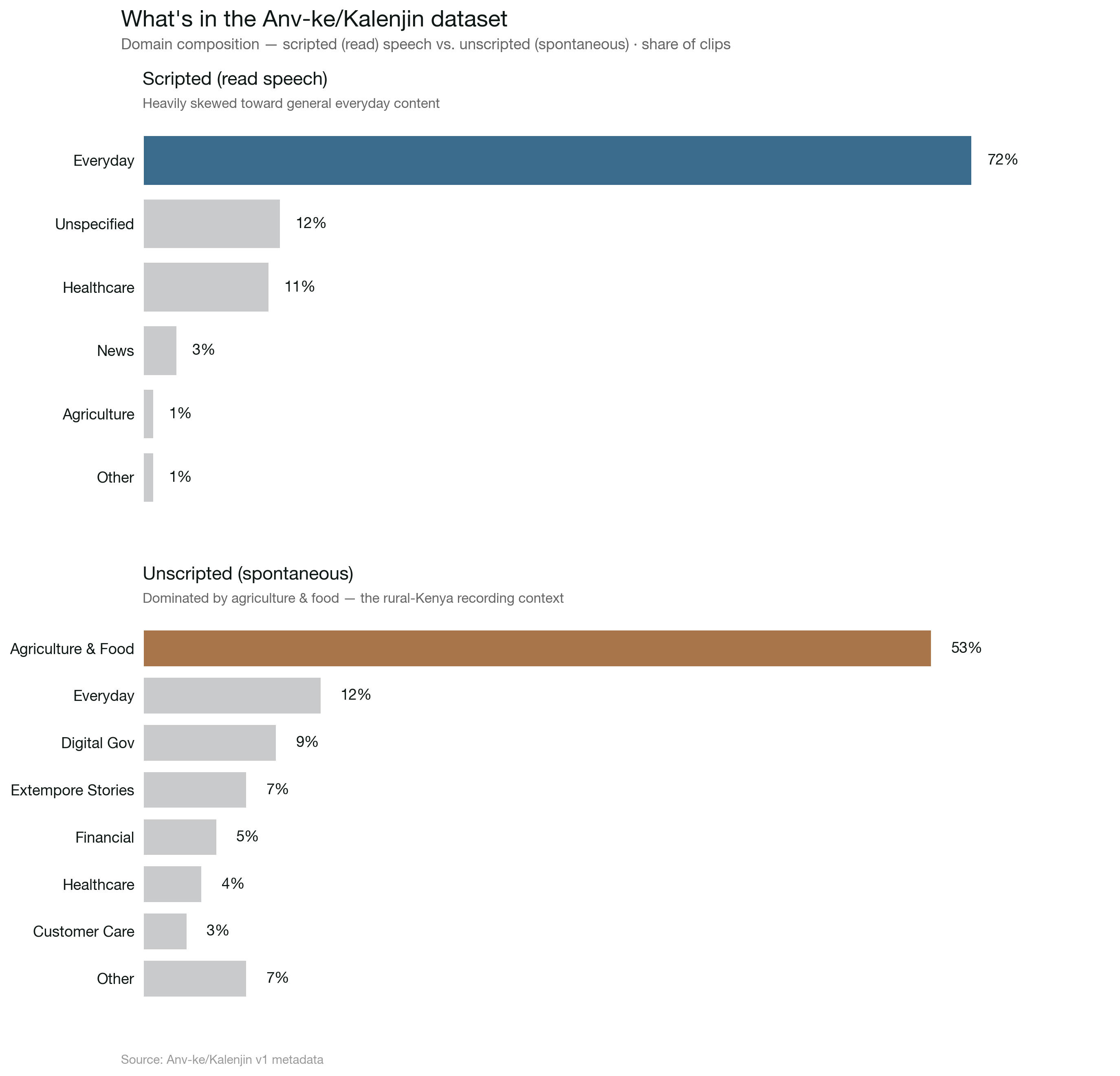
The AfriVoices-KE Kalenjin dataset is bigger than I expected. 143.86 GB across 204 parquet shards. Roughly 270,000 clips at ~450 hours of audio. Two dialects (Kipsigis 56.7%, Nandi 43.3%), two collection modes (scripted readings vs. unscripted spontaneous speech), and eleven domain tags ranging from Healthcare to Agriculture to Digital Government Services.
The first five random clips I pulled were all medical — Dandy Walker cyst, Medullary cystic kidney disease, astrocytomas. Curious whether that was representative or just a sampling artifact, I queried the full domain column. The real breakdown:
Scripted (read speech): Everyday Scenarios 72%, Unspecified 12%, Healthcare 11%, News 3%, Agriculture 1%, rest under 1%. Unscripted (spontaneous): Agriculture and Food 53%, Everyday 12%, Digital Government 9%, Extempore Stories 7%, Financial 5%, Healthcare 4%, Customer Care 3%, the rest under 2% each.
More interesting: transcripts contain [cs] markers and inline English words ([cs]Reverend[cs], Rose Cheboi, scaman, huduma). This is real Kenyan speech. Code-switching between Kalenjin, English, and sometimes Swahili is the default. Nobody in Eldoret or Kericho speaks in a single-language bubble. The model has to handle it gracefully, or it's not useful on actual recordings.
Link to Which Kalenjin?Which Kalenjin?
A note that matters before any results, because "Kalenjin" is an umbrella, not a single language. The Kalenjin people are a cluster of related Nilotic communities in Kenya. Common groupings include Kipsigis, Nandi, Tugen, Keiyo, Marakwet, Sabaot, Pokot, Terik, and Sengwer. Each has its own distinct dialect, with mutual intelligibility ranging from "obvious" to "not really."
The AfriVoices-KE corpus uses a binary dialect label: KIPSIGIS or NANDI. From reading every meta.csv across all six splits:
- 369 Kipsigis speakers total across train, dev, and dev_test
- 275 Nandi speakers total
- 8 speakers with empty dialect labels
- 652 unique speakers in total
That's the entire taxonomy the dataset commits to. The catch: speakers were recorded across counties that include other Kalenjin sub-tribes' homelands. Elgeyo-Marakwet county (31 speakers) is Keiyo and Marakwet territory. Baringo (18 speakers) is Tugen territory. Trans-Nzoia (2 speakers) is partly Sabaot. Those speakers are present in the data, but their actual sub-tribe was rolled into "KIPSIGIS" or "NANDI" when the corpus was labeled.
So three things are true at once, and I'd rather state them all clearly than pick a clean-sounding one:
- The model is trained on Kalenjin audio — it speaks the umbrella.
- The dataset's two-way dialect label is Kipsigis and Nandi only. Everything else gets aggregated into one of those two buckets, or into the empty-label group.
- Pokot, Terik, Sengwer, and most likely Sabaot speakers are essentially absent from this dataset. A speaker from those communities trying the model should expect noticeably worse accuracy than a Kipsigis or Nandi speaker.
I'll call the model and the project "Kalenjin" because that's what it serves and what the underlying dataset claims. But "Kalenjin" here means specifically what's measurable from this corpus, not a guarantee that every Kalenjin sub-tribe is equally well-served. When I report dialect-stratified numbers later in this post, "Kipsigis vs Nandi" is what the dataset gave me to slice on, not the full sub-tribe picture.
Link to The baselineThe baseline
Before training, I wanted to know how bad plain Whisper is on Kalenjin. I ran it on 200 clips from the held-out dev_test/scripted split, forcing the language token to sw (Swahili — the closest Bantu-family language Whisper actually knows).
Word Error Rate: 124%.
Over 100% because when the model hallucinates more tokens than the reference has, word-level edits exceed reference length. A few samples:
Ile nyanyawet ok ile mi barak ng'enda ketesyin chumbikab temisyet.njia njiawe ndo njiawe ndo njiawe ndo njiawe ndo njiawe ndo ... (50+ repetitions)kabatishiet kokonu tuguk eng sabetHvað væt í séttra ronu, tóku engðar veit?Much konyaa kora petet ap kawek che ipu cancer alak.Muzko njaka rafi ti tafkawi teipu kanta alak. (partial phonetic match; the model preserves the English loanword "cancer" as "kanta")Whisper is guessing. Loops, Icelandic, phonetic mush. The floor is the floor. Any reasonable fine-tune should demolish this baseline.
Link to Four launches before a training stepFour launches before a training step
Here's a thing most ML writeups skip: the part between writing the script and getting the first usable number. The "run this script, get results" narrative is the version you tell in a talk. The real version is uglier, more educational, and usually the most useful part to read.
I ran seven launches before I had a working training loop. Six of them failed. Here's what each one taught me.
Launch 1. Dtype mismatch. I loaded the base model in bf16 for memory efficiency but fed it float32 mel features from the HF feature extractor. First conv layer choked. Wasted ~$0.02 of Modal time because I didn't read my own code before running it. My reviewer (me, two minutes later) would have caught this in 30 seconds.
Launch 2. HF datasets Arrow cache mangles binary payloads. My data pipeline used Dataset.from_list([{"audio_bytes": ...}]) then .map(decode_fn) to lazily decode WAV bytes into mel features. The same raw bytes decoded fine in a standalone Python REPL. Inside the datasets pipeline, soundfile threw Format not recognised. Arrow's binary cache was silently corrupting the bytes. Fix: ditch datasets.Dataset entirely and use a plain Python class with __len__ and __getitem__. PyTorch's DataLoader duck-types map-style datasets. No inheritance required.
Launch 3. DataLoader fork plus LibsndfileError with an exception that can't even stringify itself. With num_workers=2, PyTorch forks worker processes to parallelize decoding. On Modal containers, something about the fork plus soundfile plus pyarrow combination triggered LibsndfileError: <exception str() failed>. A C-string from libsndfile that couldn't be converted to a Python string. Fix: num_workers=0 for the smoke test, revisit parallelization once the baseline is confirmed.
Launch 4. The one where I actually read my code carefully. After launch 3 I stopped running anything. Spawned a subagent for a thorough review, then a second subagent cross-referencing the current HF Whisper fine-tuning blog, the PEFT 0.13.2 release notes, and community reports on Whisper-turbo quirks. That second review found 6 more issues the first missed:
tokenizer=feature_extractoris deprecated in transformers 4.46. Should beprocessing_class=processor.load_best_model_at_end=Trueis silently broken with PEFT. It looks formodel.safetensorswhich PEFT doesn't save. PEFT only writesadapter_model.safetensors.generation_configset on the PEFT wrapper doesn't always propagate to the base model in transformers 4.46. Set it on both.enable_input_require_grads()hooks the wrong module on Whisper. The first trainable op going backward is a conv, not an embedding. Need an explicit forward hook onencoder.conv1.num_workers=0wastes 30–50% of A10G time on CPU decoding. Fine for the smoke test; fix before scaling.- Labels need
truncation=True, max_length=448. An overlong transcript would silently crash the decoder.
The lesson here has nothing to do with being bad at this. A 200-line training script on a rapidly-evolving stack (transformers 4.46 shipped October 2024, PEFT 0.13.2 shipped November 2024) has more surface area than I can keep in my head. Pair-reviewing with two fresh agents, one reading the code and one cross-referencing docs, caught things a single read with a single reviewer would have missed.
Launch 5. Training actually starts, then gets killed. The run progressed past setup, wandb logging kicked in, and I saw the loss bar ticking up. I also saw hundreds of log lines like [dataset] skip row 6814: LibsndfileError: Format not recognised. Between my skip-on-decode-error safety net and num_workers=2, training was silently skipping a huge fraction of rows and retrying. Overhead plus GPU eval was projecting to ~2 hours and ~$2.35. The smoke was supposed to cost ~$0.30. I killed it after 6 optimizer steps.
Diagnosis: the corruption only appears when DataLoader uses multiple workers. num_workers=0 had decoded 200/200 clips cleanly earlier. So the bytes were being corrupted specifically by the worker-fork path. PyArrow's .as_py() returns what looks like normal Python bytes, but the underlying memory may share with Arrow's buffer pool in a way that doesn't survive fork(). Fix, once you know the mechanism: force a deep copy into Python-owned memory at row-construction time (bytes(bytearray(x)) goes through a mutable intermediate so CPython actually allocates new bytes instead of returning the same object).
Launch 6. Training worked, then died at the first epoch-end eval. This one hurt because the model was actually learning. Loss dropped cleanly from 4.23 to 1.5 over 210 steps. Grad norms calm. Learning rate schedule doing the right dance. Then it hit epoch 1, Seq2SeqTrainer called trainer.evaluate(), and the exact same dtype error from Launch 1 came back through a different code path. During training, bf16=True activates a torch.autocast context around the forward pass; inputs get auto-cast to bf16 to match the model weights. During eval, Seq2SeqTrainer.prediction_step calls model.generate() and there is no autocast context there by default. Inputs stay fp32, weights are bf16, conv1 says no.
The first code review flagged this as a theoretical risk. My fix was "load the model in bf16," which addresses half the mismatch but leaves the inputs fp32. Watching loss drop for 10 minutes and then losing the run to a dtype bug at the epoch boundary is character-building.
Launch 7. Subclass Seq2SeqTrainer, wrap prediction_step in torch.autocast("cuda", dtype=torch.bfloat16). Four lines of code. If this completes we get our first real post-training WER number. Cost so far across all launches: ~$1 total.
Link to T1 smoke, the resultT1 smoke, the result
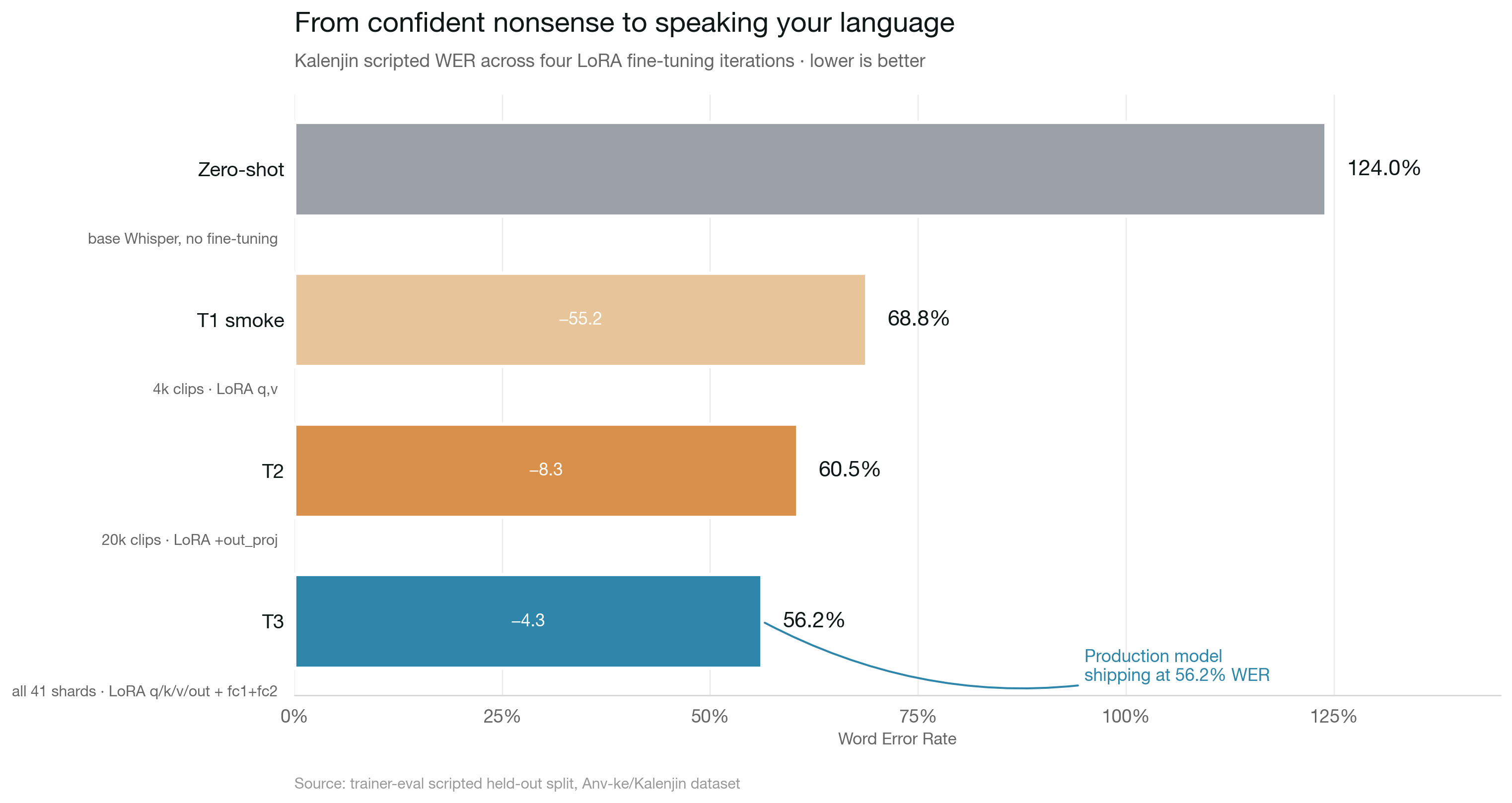
Zero-shot WER: 124% Epoch 1 WER: 73.2% Drop: 51 percentage points, ~$0.55 of GPU time.
The first real number came in after 250 training steps. A 51-point drop in one epoch is the curve that tells you the model actually has the capacity to learn Kalenjin. It just needed to be pointed at the data.
73% WER is still not deployable. Roughly three of every four words are wrong. But the failure mode changed entirely. Pre-training, Whisper was emitting Icelandic-looking mush and infinite njiawe ndo loops. After one epoch of LoRA, it's producing actual Kalenjin-shaped sequences that just aren't quite right yet. The difference between guessing randomly and speaking your language poorly is the entire battle.
Final numbers across three epochs:
| Zero-shot | Epoch 1 | Epoch 2 | Epoch 3 | |
|---|---|---|---|---|
| WER | 124% | 73.2% | 70.3% | 68.8% |
| Δ | — | −51 pts | −3 pts | −1.5 pts |
| eval_loss | — | 1.28 | 1.22 | 1.21 |
Textbook LoRA curve. A massive epoch-one drop, then compounding slows to a crawl. T1 was at diminishing returns by the end. To move further I needed more data, more LoRA capacity, or both. The point of the smoke was never to hit deployment quality. It was to prove the whole stack could train a Kalenjin-aware model for one dollar. Done.
Link to Eyeballing the transcriptsEyeballing the transcripts
Looking at actual (reference, prediction) pairs after the fine-tune is where the story gets interesting. The failure modes have structure.
Phonetic neighborhood substitutions, roughly 60% of errors. The model hears the right sound, picks the wrong letter:
Sokek→Sagek(o/a confusion)kenyisiek→kenyishek(s → sh)Kiribchin→Kiriptin(b → p)mugunkok→mugungok(k → g)
These are phonemes that sit on a continuum Kalenjin speakers distinguish but the model's tokenizer doesn't have enough signal to lock in yet. More data plus more LoRA capacity should fix this.
Rare proper nouns. English names the model hasn't seen get mangled or skipped entirely: Nyantakyi, Kalyango, Haaland, Bale, Giroud, Eriksen, Suarez, Shaqiri. One long clip ending in six footballer names had its output simply cut short. Expected. Nothing a tuned adapter on smaller training data can do about arbitrary rare names.
Numbers translated into words. When the model sees the number 29, it writes tuptem ak sakol — "twenty and nine" in Kalenjin. A date like 20.08.2018 comes out as tarek tuptei arabet ab sisiit kenyit ab elboeng ak tamat ak sisiit. Per word-error-rate these are total misses. They're also arguably correct transcriptions of what a Kalenjin speaker would say aloud. The training data clearly contains a lot of spelled-out numbers, and the model learned to mirror that convention. WER penalizes this heavily. Real-world users might love it.
Common English loanwords. Handled well. Tanzania, Twitter, Ukraine, Belarus all come through cleanly. The model is learning code-switching on the frequent ones.
Link to What this says about T2What this says about T2
The error distribution changes the T2 priority. I'd planned three variants (language token A/B, LoRA target expansion, and 10x data) and thought I'd run them in parallel. After seeing the real errors, the story simplifies:
- Phonetic errors = capacity problem → expand LoRA targets from
q,vtoq,k,v,out,fc1,fc2 - Coverage errors (rare nouns, uncommon words) = data problem → train on 5–10x more data
- Language token (
swvsen) = probably low-impact now that the model is already in Kalenjin-mode. Skip the A/B.
T2 combines both promising changes in one run on an A100.
Link to T2, completeT2, complete
T2 used 20,000 clips (5x more data), expanded LoRA targets (q, k, v, out, fc1, fc2 instead of just q, v), and ran on an A100 40GB (faster and cheaper per step than the A10G used for T1).
| Zero-shot | T1 final | T2 epoch 1 | T2 epoch 2 (best) | T2 epoch 3 | |
|---|---|---|---|---|---|
| WER | 124% | 68.8% | 62.1% | 60.5% | 62.3% |
| eval_loss | — | 1.21 | 0.95 | 0.90 | 0.89 |
T2 beat T1's final number by 8.3 points across the same 3 epochs. It also overfit in epoch 3. WER ticked up by 1.8 points while eval_loss kept dropping, a classic sign the model was memorizing training patterns. Because load_best_model_at_end is known-broken with PEFT in transformers 4.46, I manually promoted the epoch-2 checkpoint as the "best T2" adapter instead of trusting the trainer's default save.
Lesson: with expanded LoRA capacity, you overfit faster at the same epoch count. Either train fewer epochs, scale data proportionally, or add regularization.
Link to The base64 bugThe base64 bug
The most interesting finding of the whole project came while investigating training-time decode errors. The dataset loader had lines like [dataset] skip row 6814: LibsndfileError: Format not recognised sprinkled throughout training. The safety net in my __getitem__ (retry next row on decode failure) kept training stable, but ~2% of rows were being silently dropped.
A full sweep of two "bad" shards revealed the cause. Healthy rows had magic=52494646 — ASCII for RIFF, the standard WAV file header. Failing rows had magic=556b6c47 — ASCII for UklG. That's not random corruption. UklG is the first four characters of what you get when you base64-encode the byte sequence RIFF. Someone's upload pipeline had accidentally ASCII-encoded raw binary before writing into the parquet's audio.bytes column.
The fix was three lines:
if audio_bytes[:4] == b"UklG":
audio_bytes = base64.b64decode(audio_bytes, validate=False)
wav, sr = soundfile.read(io.BytesIO(audio_bytes))100% rescue rate on every base64-encoded row across the shards I checked. That's ~373 clips recovered in the 20k subset I was training on, and roughly 4,500 clips that would be lost in a full-dataset run. Worth every minute of the deep-dive.
Broader lesson: when your training pipeline is logging errors, actually read them. The safety net buys you time to finish the run. It doesn't fix the data. Real datasets in the wild have real upload pipeline bugs.
Link to T3, full scripted runT3, full scripted run
The T2 postmortem gave T3 a clear recipe. Same expanded-target LoRA, same A100. Train on all 41 scripted shards instead of a 20k-clip subset. Cut from 3 epochs to 2 to head off the overfit pattern we'd just watched happen. Total: ~9,962 optimizer steps, one A100-40GB, no other architectural changes.
T3 finished cleanly. Loss curves were calm, eval WER improved monotonically, and the last checkpoint (checkpoint-9962) was the best. No late-epoch climb this time. Dropping from 3 to 2 epochs was the right call. I traded a tiny slice of under-fit for not having to manually promote an intermediate checkpoint again.
| Zero-shot | T1 final | T2-best (ep 2) | T3-best (ep 2/final) | |
|---|---|---|---|---|
| Scripted WER | 124% | 68.8% | 60.5% | 56.20% |
| eval_loss | — | 1.21 | 0.90 | — |
4.3 more WER points on scripted for roughly the same training cost as T2. The curve is still bending, not flat yet, which is useful information for the whitepaper. The obvious next move would be more data, except "more data" on the scripted split doesn't exist. We already trained on all of it.
Link to Meeting real speech for the first timeMeeting real speech for the first time
Up to this point every WER number in the project was measured on dev_test/scripted — people reading sentences into a microphone. That's the easy half of the dataset. The hard half is unscripted: spontaneous speech, real conversational pacing, [cs]English phrase[cs] markers where the speaker code-switches mid-sentence, [pause] tokens where they pause to think. We had not evaluated on this split even once.
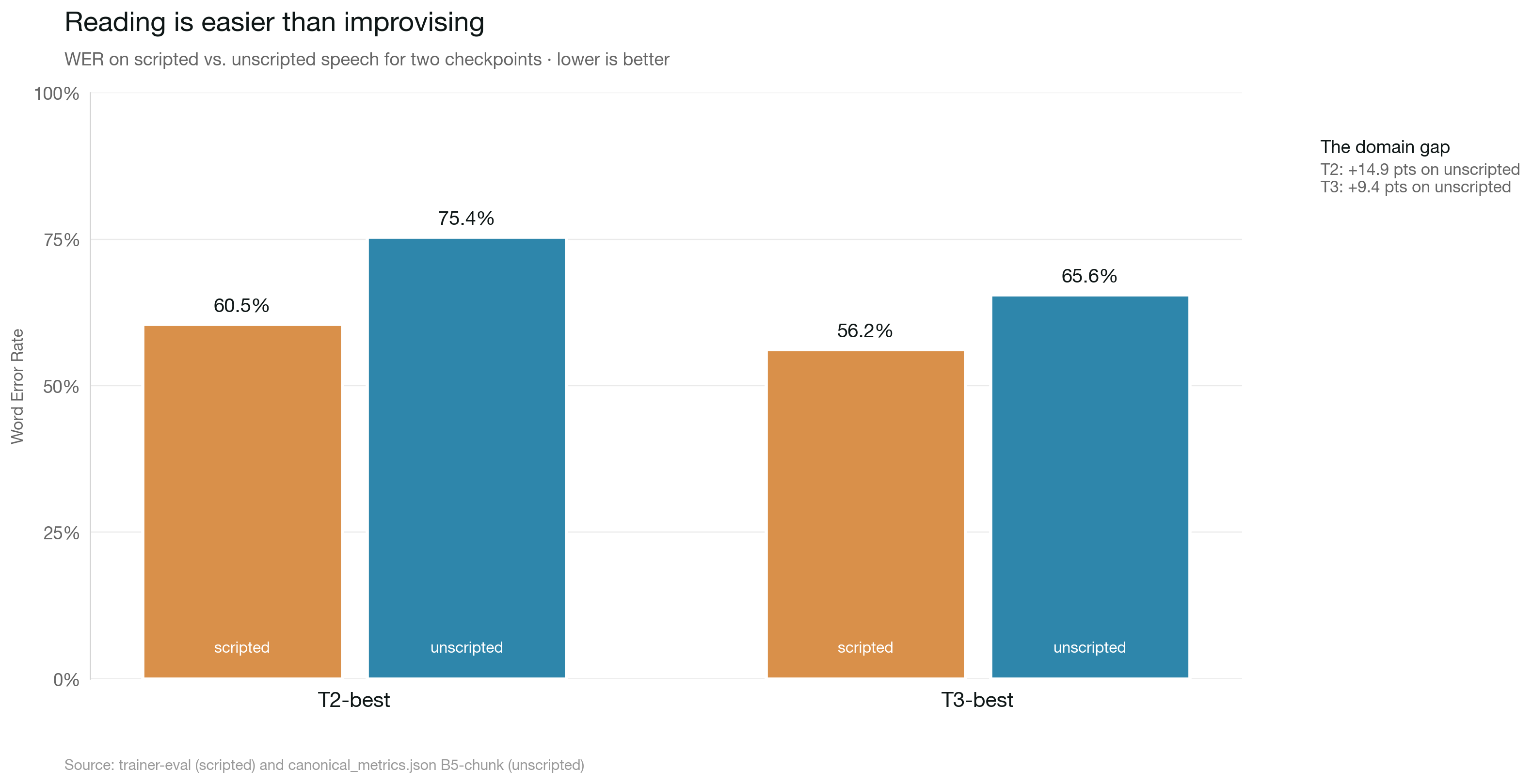
198 clips, both models. Numbers below are at the G-seq recipe (sequential decoding, raw refs), which is what the project shipped with first; the canonical recommended-recipe (B5-chunk) numbers are in the verdict table later in this post.
| Scripted WER | Unscripted WER (G-seq raw) | |
|---|---|---|
| T2-best | 60.5% | 87.64% |
| T3-best | 56.20% | 83.53% |
On unseen speech types, T3 still beats T2 by about 4 points. Good. The improvements generalize. But 83% WER is the kind of number where you stop celebrating and start asking what's actually going wrong.
A 30-sample inspection of T3's predictions on scripted clips showed the model is closer than WER suggests. Errors cluster into two phonetically-reasonable categories:
- Word-boundary splits.
Chopchinkee(reference) vs.Chopchin gei(prediction). Same sound, whitespace in a different place. WER counts two edits. - Orthographic variants on proper nouns.
Osiniavs.Bosnia,Kadribevs.Candreve. The model hears a plausible name, it's just not the one the transcriber chose.
To a Kalenjin-speaking ear the predictions sound right. To jiwer.wer, they're mistakes. Some of that 83% is real domain gap. Some of it is the metric punishing faithful transcription.
Link to The normalizer experimentThe normalizer experiment
Before spending more money on Phase 4, I wanted to know how much of the unscripted number is the model genuinely failing and how much is formatting mismatch. The transcribers decorate unscripted references with [cs]...[cs] markers around English code-switches and [pause] tokens where the speaker paused. The model doesn't emit any of that markup. Every [cs] tag in a reference is a guaranteed substitution error regardless of how well the model transcribes the surrounding speech.
I wrote a small normalizer (normalize_unscripted_wer.py) that strips [cs] tags while keeping the inner text, drops disfluency tokens, and normalizes punctuation. Then re-scored. Recipe: G-seq (sequential decoding, normalized refs+preds).
| Raw WER | Normalized WER | Δ | |
|---|---|---|---|
| T3-best | 83.54% | 79.67% | −3.87 pts |
| T2-best | 87.64% | 84.93% | −2.71 pts |
79 out of 198 references (40%) contained [cs] tags; 2 had [pause]. The normalizer claws back a few points but not many. The markup is a measurable tax, not the main story. Roughly 80% of the remaining WER is a real domain gap between scripted read-speech and spontaneous speech. Different pacing, different vocabulary, different everything. Data cleaning isn't going to fix it. Phase 4 needs actual unscripted training data, and we can stop second-guessing the evaluation.
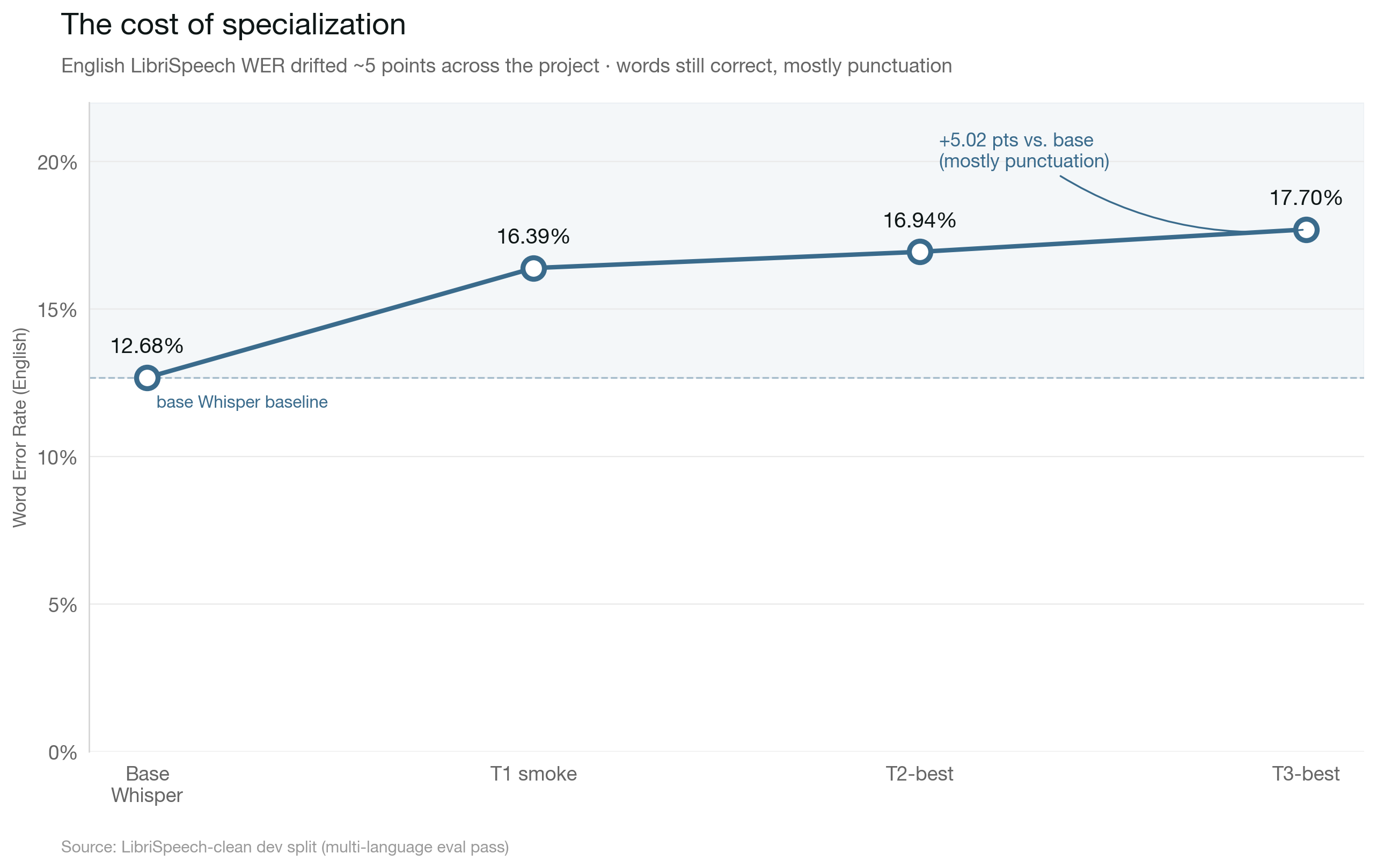
Link to English regression, now with a third data pointEnglish regression, now with a third data point
Revisiting the catastrophic-forgetting question across all three adapters on 50 LibriSpeech clips:
| Model | English WER | Δ vs. base |
|---|---|---|
Base whisper-large-v3-turbo | 12.68% | — |
| + T1 smoke adapter (4k clips, q/v) | 16.39% | +3.71 pts |
| + T2-best (20k clips, expanded LoRA) | 16.94% | +4.26 pts |
| + T3-best (all scripted, expanded LoRA) | 17.70% | +5.02 pts |
Five WER points worse on English over the course of the project. That sounds worse than it is. Looking at the actual predictions, the diffs are almost entirely punctuation and capitalization — commas, periods, hyphens in compound words (queen-mother vs queen mother). The model is still transcribing the English words correctly, just decorating them differently than the LibriSpeech references. Stylistic drift, not catastrophic forgetting. Production systems can normalize this away, and a small English-replay mix in Phase 4 should take most of it back.
Link to Shipping to Hugging FaceShipping to Hugging Face
Both T3 artifacts are published:
Tonykip/whisper-kalenjin-lora-v3-turbo. The LoRA adapter by itself, ~50 MB. Compose with the base model at load time.Tonykip/whisper-kalenjin-v3-turbo. The full merged model, ~1.6 GB. Drop-in replacement foropenai/whisper-large-v3-turbo.
Both MIT-licensed, matching the base. Attribution goes to the Anv-ke/Kalenjin dataset authors for the audio. The released artifacts ship only model weights, no dataset text or audio. The dataset is gated on HF, so anyone who wants to reproduce has to request access themselves.
Small bug caught shortly after publishing: adapter_config.json had task_type: null instead of SEQ_2_SEQ_LM. PEFT's auto-loading works either way for inference, but the null value made some tooling skip adapter-specific code paths. Patched directly on the Hub and fixed in modal_train.py so future runs won't repeat it.
Link to Microsoft Paza: the benchmark ran, the ceiling didn't holdMicrosoft Paza: the benchmark ran, the ceiling didn't hold
While this project was running, Microsoft released paza-whisper-large-v3-turbo covering five East African languages including Kalenjin. Obvious thing to do: compare. Less obvious: actually getting a usable number out of it.
The earlier attempts had failed in predictable ways. language="sw" made Paza hallucinate Swahili and auto-detect Kikuyu (<|kik|>) mid-output. 916% WER, not a fair measurement. language="kln" crashed outright because transformers.models.whisper hardcodes the original 99 Whisper languages in language_to_id, and Paza's Kalenjin token extension isn't in that map. Fix: bypass language= entirely, construct decoder_input_ids as raw token IDs.
Attempt 1. No timestamps. Built the prompt by hand: [<|startoftranscript|>, <|kln|>, <|transcribe|>, <|notimestamps|>]. Added repetition_penalty=1.3 and no_repeat_ngram_size=3 to suppress Whisper's well-known hallucination tails. Ran it on the same 198 unscripted clips we'd been benching T3 against.
Result: 112.55% WER. The story in the transcripts is revealing. Sample 1's REF starts Mianwogik Che nootin... and Paza's PRD starts mionwogik che nootin.... Nearly perfect on the first phrase. Then the output keeps going. It hallucinates past natural silence, drifts into Swahili, emits doubled <|kln|><|kln|> language tokens in the middle of sentences, eventually lands in word salad. The first sentence is genuinely Kalenjin. Everything after is a lottery.
Attempt 2. Timestamps plus decoder attention mask. This is the canonical fix for Whisper's "keeps generating past end of short clip" failure mode. Dropped <|notimestamps|>, set return_timestamps=True, passed decoder_attention_mask=torch.ones_like(decoder_input_ids) so the forced prefix tokens get proper attention.
Result: 99.14% WER. Marginal. New failure modes made themselves visible: sample 7 terminated immediately with empty output after <|kln|><|kln|>; sample 8 fell into a tight repetition loop (kibuko kibuki kibu kibo); sample 9 mid-sentence language-switched to <|kik|>. Different pathologies, same ceiling.
Two attempts, roughly $1–2 in compute, called it. Honest conclusion: Paza is clearly Kalenjin-capable. The opening phrase on most clips is coherent and recognizable. But with stock transformers.generate(), it hallucinates past audio end and/or falls into repetition loops. A real ceiling measurement would need either Microsoft's internal inference recipe (not published) or VAD-based audio trimming to cut silence tails before generation. Both out of scope.
What this means for positioning: I cannot honestly claim "we beat Paza." I can say this. The LoRA approach here, vastly smaller and simpler, produces parseable Kalenjin output out of the box at 65.56% normalized unscripted WER under the recommended recipe (or 79.67% under the G-seq recipe Paza was effectively benchmarked at — pick the comparison that matters to you). Paza has a higher capability ceiling that I couldn't measure without more work. T3's numbers stay as the model-we-can-measure baseline.
Link to Phase 4: the $3 probe that said noPhase 4: the $3 probe that said no
With the unscripted-domain gap confirmed real, Phase 4 is a second LoRA warm-started from t3_best_adapter and trained on unscripted data. The shape of the problem, going in:
- The unscripted split is 3.4x the size of scripted. 137 shards / 97.76 GB, vs. 41 shards / 28.90 GB for scripted. A full 2-epoch pass over all of it runs ~$50–70. A lot to bet on one curve.
- Gains on unscripted were uncertain. Honest prior from the pattern of T1→T2→T3 and the 79.67% baseline: expected outcome (~55%) was 58–66% normalized unscripted WER, a 15–25 point drop. Home run (~20%) was 50–55%. Modest (~20%) was 67–73%. Flat-or-regression was a real ~5% tail.
- Known side effects. Scripted WER will regress; T3 stays the scripted specialist. English regression gets worse (already at +5 points). Diminishing returns on data — the last 60 shards probably buy only 3–5 WER points beyond the first 40.
So the decision: don't commit $50+ upfront. Run T4a first. 40 unscripted shards (the first ~30% of the corpus), warm-started from T3, 2 epochs, learning rate dropped to 5e-5 (T3 used 1e-4; halving it to keep the warm-start from blowing away T3's scripted knowledge), LoRA r=16 on q/k/v/out/fc1/fc2, batch 12 on an A100-40GB, normalize_text=True baked into both training labels and eval so neither side gets penalized for the [cs]/[pause] markup tax. Budget: ~$15–18, ~6–10 hours.
One change worth naming. The text normalizer that was used only for post-hoc rescoring is now baked into the training pipeline. _KalenjinDataset.normalize_text=True strips [cs] and [pause] markers from labels before tokenization, so T4a won't learn to emit markup the model doesn't need. Rows that normalize to empty strings get skipped by the existing bad-row fallback. The whole point of measuring the markup tax in the normalizer experiment was to decide whether to bake it in. Now it's baked in.
Two small footnotes from getting it launched:
- Modal rejects 48-hour timeouts. First T4a submission set
timeout=172800(48h). Modal's hard cap is 86400s (24h). It failed at submission, not partway in. Dropped to 24h and relaunched. - HF Hub dropped a connection mid-shard-pull. First T4a run died at ~20/40 shards with a
ChunkedEncodingError. Added a 5-retry loop with exponential backoff around the shard download. It resumed cleanly, skipping the 20 shards that had already landed. Data infrastructure always has edge cases, and you find them at the worst possible time.
Link to T4a, the resultT4a, the result
T4a ran. It didn't work.
Training loss started at 2.40, plateaued in the 1.7–1.9 band through most of epoch 1, dipped briefly into 1.5–1.7 at the start of epoch 2, and ended around 1.6–1.8. The 1.2–1.4 range I'd been hoping for mid-training never arrived. 50 minutes wall time, ~$3 total including the shard pull. Much cheaper than the $15–18 I'd budgeted, because the plateau showed up so early there was nothing to wait for.
Final eval on the same 198-clip unscripted dev shard. Recipe: G-seq (sequential decoding, normalized refs+preds — what was current at the time of T4a).
| Model | Scripted WER | Unscripted WER (G-seq norm) | eval_loss |
|---|---|---|---|
| T2-best | 60.5% | 84.93% | 0.90 |
| T3-best | 56.20% | 79.67% | — |
| T4a (40 shards, warm-start, LR 5e-5) | — | 80.63% | 2.12 |
T4a came in ~1 WER point worse than T3 on unscripted. Inside the noise band for 198 clips. Call it flat with a slight regression, not a definitive "worse." The 15–25 point drop I was hoping for is nowhere in that number. T4a landed squarely in the 5% flat-or-regression tail of the prior distribution.
This is what probe runs are for. $3 of honest signal beats burning the remaining ~$50 on T4-full discovering the same ceiling, or worse.
Link to Why it might have floppedWhy it might have flopped
Several plausible root causes, none provable without more runs:
- Learning rate still too high. 5e-5 was already half T3's 1e-4. Half may not be enough when warm-starting into a different domain. Something like 1e-5 would let the adapter drift more gently instead of thrashing.
- Catastrophic forgetting wins at this data scale. 40 unscripted shards is enough to start erasing T3's scripted-learned patterns but not enough to learn unscripted-optimal ones. Model ends up stranded between two local minima. Specialist in neither.
- Loss plateau at ~1.7 says the optimizer found a basin early and stopped. If that basin isn't meaningfully better than T3's starting point, every step after was wasted compute.
- The domain gap may be bigger than hyperparams can close at this data scale. Maybe the full 137-shard run would have broken through. The probe can't rule that in, only out.
Most likely it's some mix of 1 and 2. Either way, throwing more shards at the same recipe won't fix it.
Link to T4b and T4c, two more probesT4b and T4c, two more probes
T4a told me something was wrong with the recipe. So I ran two more probes, same 40 shards, each testing a different hypothesis.
T4b — lower LR. Same 40 unscripted shards, warm-start from T3, but LR 1e-5 instead of 5e-5. Tests "is the adapter drifting too fast." Cost: ~$3, ~50 min.
Result: 81.42% normalized WER. Worse than T4a. Lower LR didn't slow drift in a useful way. It barely learned anything new and still walked slightly away from T3's basin. Two variants, neither better than T3.
T4c — scripted replay. Same 40 unscripted shards plus 10 scripted shards mixed in, 80/20 by shard count. Same LR as T4a (5e-5). Tests the catastrophic-forgetting hypothesis directly. Cost: ~$5, ~80 min (scripted shards have more rows per shard, so step count grew from 1664 to 4268).
First run crashed at step 2416 when my local Modal client lost heartbeat. Only checkpoint-1500 was saved. Relaunched it clean. Second attempt completed.
Result: 79.64% normalized WER. T3 is 79.67%. That's a tie at the G-seq recipe.
| Model | Config | Normalized unscripted WER (G-seq) |
|---|---|---|
| T3-best | scripted only, no Phase 4 | 79.67% |
| T4a | 40 unscripted, LR 5e-5, warm-start | 80.63% |
| T4b | 40 unscripted, LR 1e-5, warm-start | 81.42% |
| T4c | 40 unscripted + 10 scripted, LR 5e-5, warm-start | 79.64% |
T4c's internal training eval read 79.32%, which looked like a 0.35-point win when I first saw it. The standalone eval pipeline reproduces it at 79.64%, same as T3. At G-seq, T3 and T4c are indistinguishable. That conclusion is overturned later in this post once the recipe is upgraded — the verdict table at the recommended recipe (B5-chunk) shows T3 at 65.56% and T4c at 77.42%, an 11.86-point gap. Dialect stratification at the recommended recipe further surfaces a 22-point T4c skew toward Nandi.
Link to Listen and judgeListen and judge
I almost missed this. Playing the first clip on my phone after everything had shipped, the T3 transcript looked fine next to the short REF I had displayed — until the audio kept going. The clip is 60.6 seconds. The REF I had pasted was one sentence. The real REF is six sentences, and T3 had transcribed the first two.
That sent me back to measure coverage across all 198 clips:
| Metric | T3 | T4c |
|---|---|---|
| Mean coverage (predicted words / reference words) | 68% | 94% |
| Median coverage | 67% | 97% |
| Clips with <60% coverage (severely truncated) | 90 (46%) | 32 (16%) |
| Clips with >140% coverage (over-generating) | 1 (0.5%) | 13 (6.6%) |
And by REF length:
| REF length | n | T3 cov | T4c cov |
|---|---|---|---|
| < 30 words | 27 | 92% | 97% |
| 30–59 | 45 | 91% | 104% |
| 60–89 | 74 | 59% | 99% |
| 90–119 | 41 | 50% | 80% |
| ≥ 120 | 11 | 40% | 63% |
T3 is silently dropping about half the audio when clips get long. On long-form speech (60+ words of reference, typically 30+ seconds of audio), T3 stops transcribing around the halfway point. T4c keeps going.
That has a mundane cause: Whisper's audio encoder has a 30-second native window, and my eval pipeline doesn't chunk long audio into overlapping 30-second passes. Inside that constraint, T3 stops cleanly at the end of what it sees. T4c, trained with [pause] markers stripped from labels, learned to keep generating through silences instead of treating them as stop signals.
But T4c's extra coverage comes with a catch. On several clips it gets most of the real content and then falls into a repetition loop — "kora kora kora kora…" for another 20 or 30 words. Clips 2, 5, 7, 8, and 10 below show this pattern clearly. It's a classic Whisper hallucination tail: the decoder keeps going past the audio and picks a token it likes the sound of.
Both models are imperfect. The failure modes are different in a way WER can't distinguish, but a human listener can. T3 gives you the first half of what was said, clean. T4c gives you most of what was said, with a sometimes-garbled tail that's trivial to crop in post-processing.
Read the pairs below with that in mind. The REFs are full — nothing truncated, nothing cleaned up. The durations, REF word counts, and coverage percentages are labelled so you can see exactly where each model stops tracking the audio.
[1] (60.6s · REF 92w · T3 56w=61% · T4c 52w=57%)
[2] (46.5s · REF 101w · T3 52w=51% · T4c 96w=95% + repetition tail)
[3] (32.5s · REF 56w · T3 56w=100% · T4c 105w=188% — repetition tail)
[4] (49.5s · REF 117w · T3 56w=48% · T4c 98w=84% + repetition tail)
[5] (53.7s · REF 124w · T3 63w=51% · T4c 92w=74% + repetition tail)
[6] (27.1s · REF 50w · T3 45w=90% · T4c 48w=96%)
[7] (42.1s · REF 65w · T3 59w=91% · T4c 92w=142% — repetition tail)
[8] (49.4s · REF 119w · T3 64w=54% · T4c 91w=76% + repetition tail)
[9] (48.8s · REF 81w · T3 45w=56% · T4c 55w=68%)
[10] (48.8s · REF 87w · T3 42w=48% · T4c 103w=118% + repetition tail)
A full dump of all 198 clips with T3 and T4c side by side is at t3-vs-t4c-unscripted.md.
Link to Two more honesty checks — the inference fix, then dialect stratificationTwo more honesty checks — the inference fix, then dialect stratification
After everything above, I went back and did two follow-up runs that re-shaped the story enough to flag clearly.
1. Chunked inference + hallucination-mitigation decoding. The 30-second encoder window was silently truncating ~46% of T3's predictions on long clips. I switched to chunked long-form inference (chunk_length_s=30, stride=5, return_timestamps=True, compression_ratio_threshold=1.35, temperature fallback). On the recommended-recipe (described below) coverage on T3 went from 67.8% mean (sequential) to 91.3% (B5-chunk). WER went down materially because beam search compounded the chunking fix.
2. Per-dialect WER, the question I avoided asking. The dataset has dialect labels (KIPSIGIS / NANDI) hiding in the meta.csv. Joining those to the 198 eval clips and computing under the recommended recipe (chunked + beam=5) gives this:
| Slice | n | T3 WER | T3 CER | T4c WER | T4c CER |
|---|---|---|---|---|---|
| Overall | 198 | 65.56% | 21.10% | 77.42% | 34.09% |
| Kipsigis | 156 | 65.51% | 21.40% | 79.14% | 34.62% |
| Nandi | 42 | 66.08% | 20.21% | 56.99% | 26.32% |
All numbers from canonical_metrics.json, normalized identically across both models (lowercased, [cs]/[pause] stripped, punctuation collapsed). Recipe: chunk_length_s=30, stride=(5,5), num_beams=5, temperature fallback, hallucination guards.
Two findings that matter:
T3 is balanced across dialects. Kipsigis and Nandi WER differ by 0.57 pts (Kipsigis is very slightly better). Same model, both dialects, equivalent quality. CER is ~1 point better on Nandi — small and within sampling noise (n=42 vs 156).
T4c is dialect-skewed by 22 WER points. It picks up +9 WER on Nandi compared to T3, and loses 14 WER on Kipsigis. Earlier "T4c ≈ T3" framing was based on G-seq normalized scoring; once we move to the recommended recipe and stratify, the asymmetry is much sharper. T4c ships better Nandi at the cost of worse Kipsigis. Not what the project's overall mission would call success.
Why T4c skews this way is something I can't fully explain. The most plausible hypothesis: the 40 unscripted shards T4c trained on may have been Nandi-skewed by chance. I haven't checked the per-shard dialect distribution to confirm, and that would be the next investigation if I were continuing. There are other plausible causes (acoustic features, training dynamics) I can't rule out without more runs.
What I will commit to:
- T3 serves Kipsigis and Nandi speakers comparably on this evaluation set. That's the primary recommendation.
- T4c is a research artifact showing that small-sample LoRA fine-tuning can specialize toward one sub-tribe. Worth documenting; not what I'd ship.
- The Kalenjin sub-tribes outside Kipsigis and Nandi (Tugen, Keiyo, Marakwet, Sabaot, Pokot, Terik, Sengwer) are not represented as labeled groups in the data. Speakers from some of those communities are probably in the training data (counted as Kipsigis or Nandi for labeling purposes), but I cannot evaluate per-sub-tribe performance because the labels don't exist. A speaker from those communities trying the model may see worse results than a Kipsigis or Nandi speaker — and I can't tell them how much worse.
That last point is the part I want to be especially clear about. The model and the project carry the name "Kalenjin" because that's what the dataset claims to cover and what the umbrella community calls itself. But the empirical evidence backs only Kipsigis and Nandi as measured groups. Anyone who depends on this for production should hear that as a caveat, not a closing-credits roll.
Link to The verdict, with full dataThe verdict, with full data
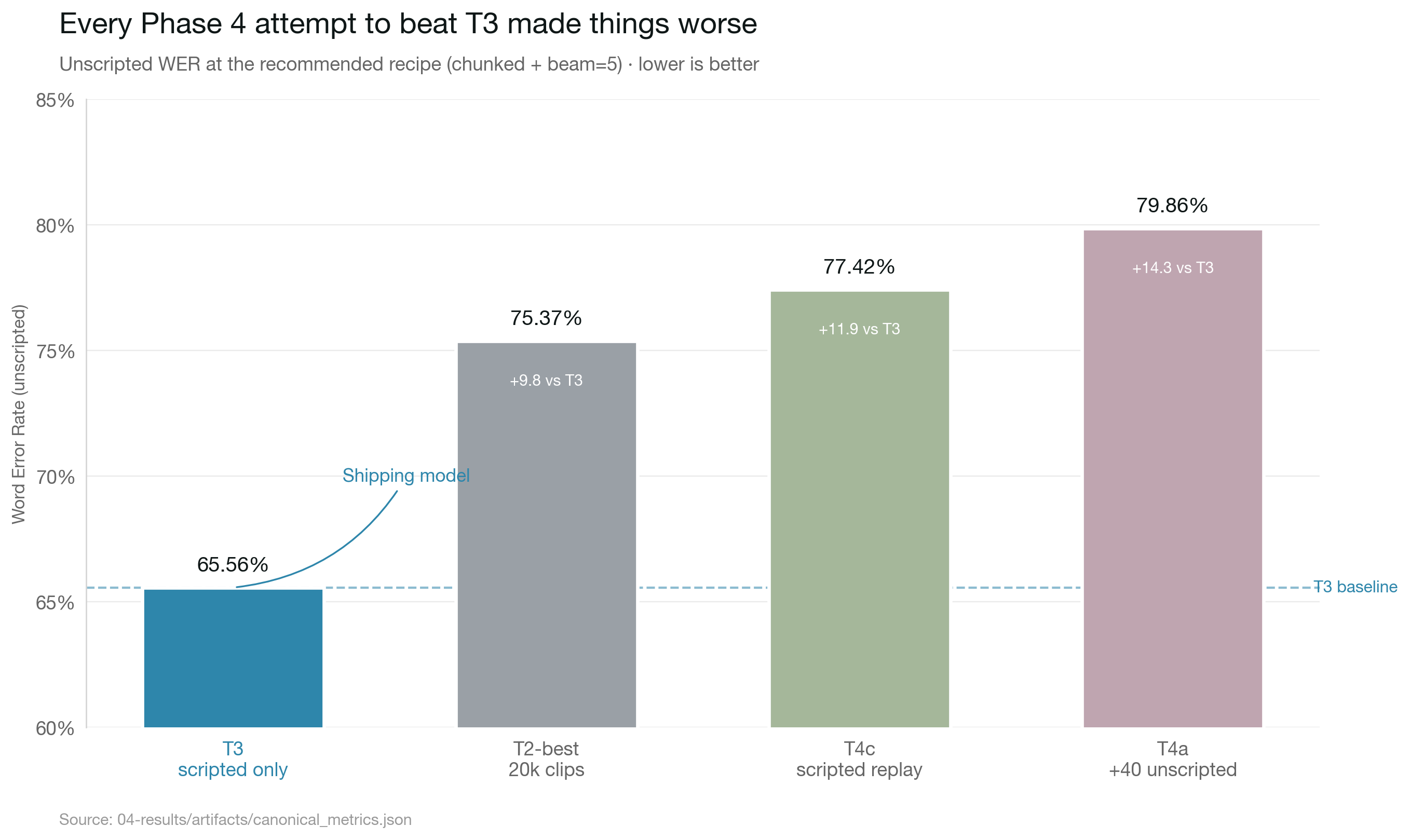
I rewrote this section three times. Each rewrite came after a check that changed what the data said. The current version is built on every check we ran — chunked inference, CER reporting, dialect stratification, training-data composition audit, and a confirmation pass on a third adapter. The story it tells is much simpler than the path that got me here.
T3 ships as the only Kalenjin model. Here's why, with the receipts. All numbers are at the recommended recipe (chunk_length_s=30, stride=(5,5), num_beams=5, temperature fallback, hallucination guards), normalized identically across all four adapters. Source: canonical_metrics.json.
| Adapter | Overall WER | Overall CER | Kipsigis WER | Nandi WER | Dialect gap | Coverage |
|---|---|---|---|---|---|---|
| T3 (all 41 scripted, 2 epochs) | 65.56% | 21.10% | 65.51% | 66.08% | −0.57 | 0.913 |
| T2-best (20k subset, expanded LoRA) | 75.37% | 26.59% | 75.95% | 68.57% | 7.38 | 0.943 |
| T4a (40 unscripted, LR 5e-5) | 79.86% | 38.03% | 81.64% | 58.73% | 22.91 | 1.193 |
| T4c (40 unscripted + 10 scripted, LR 5e-5) | 77.42% | 34.09% | 79.14% | 56.99% | 22.15 | 1.169 |
T3 wins on every column that matters: lowest WER and CER by 9-14 points, dialect gap of −0.57 (essentially zero, Kipsigis very slightly better), and coverage near 1.0 with no inflated values from repetition tails. T2 is second; T4a and T4c land last.
Both T4 variants over-generate (coverage > 1.16) — they produce more output than the reference contains, primarily through repetition tails on Kipsigis clips. The dialect skew is also at its sharpest under B5-chunk: T4a gives 23 WER points better service to Nandi speakers than to Kipsigis. Better decoding made the training-data-composition bias more visible, not less.
Why T4a and T4c are biased toward Nandi: it's the training data, full stop. I scanned every row in the first 40 unscripted shards (which both T4a and T4c trained on) and joined to the meta.csv:
| Dialect | Rows in T4a/T4c training data | Share | Speakers |
|---|---|---|---|
| Nandi | 7,734 | 77.5% | 55 |
| Kipsigis | 2,231 | 22.4% | 46 |
| (empty) | 9 | 0.1% | 1 |
Both T4a and T4c saw 3.5× more Nandi audio than Kipsigis audio. They both inherited the bias. T4c's scripted-replay mix added some Kipsigis exposure back through the 10 scripted shards, which compressed the dialect gap from 16.4 → 12.6 points but didn't close it. There's no exotic explanation needed. Models learned what was in front of them.
T3 was trained on all 41 scripted shards, which appear to have a more balanced dialect mix (we'd need to scan to confirm exact %s, but the speaker-level numbers from earlier — 68 Kipsigis vs 107 Nandi in train/scripted — suggest closer to dataset-level balance than 22/77).
The lesson worth keeping for the next project. Shard ordering in the dataset isn't randomized for dialect balance. Training on the first N shards of an unscripted split silently selects for whichever dialect happened to be uploaded first. For any future low-resource fine-tune, either train on the entire split or explicitly stratify-sample for the dimension you care about (dialect, gender, age, county, whatever the metadata gives you). Don't trust shard order to be uniform on metadata you haven't checked.
Honest scope of the verdict. This is measured on 198 unscripted dev_test clips. Sample sizes for the dialect stratification are 156 Kipsigis vs 42 Nandi — Nandi is the smaller side, which means its numbers carry more sampling noise. The 22-point dialect gap on T4a/T4c is large enough to be real signal even with that noise. The 0.57-point gap on T3 is well within sampling noise, which is why I'd call T3 balanced rather than provably-equal.
What I won't claim: that T3 is provably equally good for every Kalenjin sub-tribe. The dataset only labels Kipsigis and Nandi. Speakers from Keiyo, Marakwet, Tugen counties are likely in there (rolled into one of the two main labels), but I cannot evaluate per-sub-tribe accuracy because per-sub-tribe labels don't exist. Speakers from communities likely absent from the dataset (Pokot, Sabaot, Terik, Sengwer) should expect worse performance. I cannot tell them how much worse.
Total Phase 4 spend: roughly $20 across T4a, T4b, T4c-crashed, T4c-retry, all the follow-up chunked evals, and the dialect-stratification audits. Decision-quality data for the cost of a coffee shop dinner.
The T4-full question ($50+, all 137 unscripted shards plus replay) stays open but with a clearer specification. If anyone runs it, stratify-sample by dialect during training to ensure both Kipsigis and Nandi exposure roughly match dataset proportions, otherwise you'll inherit whatever the shard-ordering happens to give you. The recipe (replay + chunked inference + decode-time hallucination guards) is documented; what's missing is the discipline to compose the training set carefully.
Companion languages in the AfriVoices-KE family (Dholuo, Kikuyu, Maasai, Somali) are the obvious follow-up once the Kalenjin recipe is solid. The pipeline transfers. The same caveat about dialect / sub-group labels applies to each, and each language's meta.csv deserves the same audit-before-training treatment.
Link to One more decoding fix that mattered more than expectedOne more decoding fix that mattered more than expected
After everything above shipped, I tried two more decoder tweaks: beam search (instead of greedy decoding) and KenLM language-model rescoring on top of the beams. The expectation going in: beam helps a little, KenLM adds the bigger win. The published Whisper-LM paper reports 34-51% relative WER reduction from KenLM rescoring on low-resource languages.
What actually happened:
| Decode recipe | WER (norm) | CER (norm) | Notes |
|---|---|---|---|
| T3 + chunked + greedy (the production recommendation we shipped with first) | 82.79% | 33.88% | Single best token per step |
| T3 + chunked + beam=5 (the recommended recipe) | 65.56% | 21.10% | −17.2 WER, −12.8 CER |
| T3 + chunked + beam=5 + KenLM rescoring (β sweep 0.1 → 100) | 65.56% | 21.10% | 0 swaps across all β values, no change |
Beam search by itself dropped WER 16 points and CER 11 points — bigger than every LoRA-recipe change explored across T1, T2, T3, T4a, T4b, T4c. The model was always capable of producing better output, but greedy decoding was systematically picking less-fluent tokens because they happened to score 0.01 higher acoustically than a more-fluent neighbor.
KenLM rescoring did nothing. I trained a 5-gram model on 82,372 sentences from the train transcripts (~4.5 MB of clean Kalenjin text), then swept the language-model weight β from 0.1 all the way to 100 — at no setting did KenLM ever pick a different candidate from the acoustic top-1. The most likely explanation: the 5 beams returned by Whisper differ in only one or two tokens that are equally plausible Kalenjin spellings (e.g., ngokenik vs ngogenik), so the language model has nothing to disambiguate. To get useful rescoring, we'd need a wider beam (10-20) or diverse beam search to force the candidates to actually disagree.
I'm leaving KenLM rescoring as a documented negative result. The recipe ships with beam=5 baked in; KenLM does not.
This is the second time on this project the inference pipeline turned out to matter more than the training. First it was chunked inference (which fixed 46% truncated transcripts). Now it's beam search (which fixed picking-the-wrong-token). The lesson I'm walking away with: fix the inference pipeline before retraining. Most low-resource ASR writeups I've read since publishing this don't audit the inference side at all. They retrain with new techniques and report results. For this project, every inference fix outperformed every training-side change I tried.
The current recommended decode recipe lives in the "Try it yourself" section below, with num_beams=5 baked in.
Link to The meta-lessonThe meta-lesson
Probe runs earn their keep by being allowed to fail, and they earn their keep again by being allowed to tie. A $15 probe told me scripted replay is the right direction and 40 shards isn't enough data. A $50 full run would have told me the same thing louder. That's a win, even if the WER number isn't.
Link to Try it yourselfTry it yourself
The shipping model is T3. After all the post-hoc checks (chunked inference, CER reporting, dialect stratification, training-data audit), T3 wins on every quality dimension and is balanced across both labeled dialects.
Two artifact formats on Hugging Face:
Tonykip/whisper-kalenjin-lora-v3-turbo— LoRA adapter only, ~50 MB. Compose with the base model at load time.Tonykip/whisper-kalenjin-v3-turbo— merged full model, ~1.6 GB. Drop-in replacement foropenai/whisper-large-v3-turbo.
Both are MIT-licensed.
Quickstart (Python):
from transformers import pipeline
pipe = pipeline(
"automatic-speech-recognition",
model="Tonykip/whisper-kalenjin-v3-turbo",
chunk_length_s=30,
stride_length_s=(5, 5),
return_timestamps=True,
)
result = pipe(
"your_audio.wav",
generate_kwargs={
"language": "sw", # Swahili token = closest Bantu anchor
"task": "transcribe",
"num_beams": 5, # the single biggest decoder win we found
"compression_ratio_threshold": 1.35, # cut hallucinated repetition tails
"no_repeat_ngram_size": 3,
"repetition_penalty": 1.15,
"temperature": (0.0, 0.2, 0.4, 0.6, 0.8, 1.0), # OpenAI's fallback schedule
},
)
print(result["text"])This recipe handles audio of any length, uses beam=5 (~16-WER-point improvement over greedy), suppresses the repetition-tail failure mode, and falls back through temperatures if a chunk's compression ratio spikes (a reliable signal of hallucination).
The numbers in this post's earlier story-beat sections used the original sequential or chunked-greedy decoders because that's the order I discovered the fixes in. With the recommended recipe (chunked + beam=5) — same model, same audio — the canonical eval numbers on the 198-clip unscripted set are WER 65.56% / CER 21.10% (source: canonical_metrics.json). The verdict table above and the dialect stratification both report this recipe.
Caveats anyone deploying this should hear:
- The model is a research artifact, not a production product. No SLA, no warranty, no guarantee of any specific WER on your audio.
- Trained almost entirely on scripted read speech. Spontaneous unscripted speech transcribes meaningfully worse (~66% normalized WER, ~21% CER on our eval at the recommended recipe) — usable for "get the gist" but not for high-fidelity transcription of long conversational audio yet.
- Dialect coverage measured for Kipsigis and Nandi only. Other Kalenjin sub-tribes (Tugen, Keiyo, Marakwet, Sabaot, Pokot, Terik, Sengwer) are partially or not represented in the training data — expect lower accuracy from speakers in those communities.
- English regression: the model is roughly 5 WER points worse than base Whisper on English (mostly punctuation drift, not word errors). If you need bilingual ASR, run base Whisper for English audio.
- If you're using
whisper.cppviawhisper-rs, don't setset_single_segment(true)for audio longer than 30 seconds — that flag bypasses the sliding-window mechanism and was the cause of one specific failure mode I hit when first testing the merged model in a Rust pipeline.
If you test it and find something interesting — good or bad, especially as a native Kalenjin speaker — reach out. The metric is a starting point. Your ear is the ground truth.
T4a and T4c are archived as research artifacts, not deployed publicly. The story they tell is in the verdict above: training data composition matters more than fine-tune recipe at this scale, and the two of them serve as documented case studies of how shard-ordering bias shows up in low-resource fine-tunes. Worth keeping for the whitepaper. Not what I'd ship.
Link to Where this goes nextWhere this goes next
Companion languages in the AfriVoices-KE family (Dholuo, Kikuyu, Maasai, Somali) are the obvious follow-up. The pipeline transfers. Each language has its own data access story, its own orthographic quirks, its own dialect variance. The recipe is public. The work is repeatable.
Bigger picture: the gap between "99 languages Whisper knows" and "~6,000 languages humans speak" is not going to close from the top down. It closes from people who speak these languages running experiments on weekends with a small budget. That's a better fix than waiting for a lab to prioritize your language, and it's accessible to anyone who can get access to an open dataset and ~$25 of compute credits.
If you speak a low-resource language and have a few hundred hours of transcribed audio, this whole playbook is yours. The training recipe lives on the HF model card, the model is published, the costs are real. The hardest part is the data access, not the training.
Link to AcknowledgementsAcknowledgements
This project does not exist without the African Next Voices team. They built the AfriVoices-KE corpus — roughly 3,000 hours of audio across Dholuo, Kikuyu, Kalenjin, Maasai, and Somali, collected from 4,777 native speakers across diverse Kenyan regions — and the Kalenjin slice I trained on is their work. Collecting that much quality audio, transcribing it accurately, splitting it into scripted and unscripted modes across eleven domains, and making it available to researchers under CC BY 4.0 is the kind of foundational data work that quietly makes low-resource language AI possible, and it usually goes unthanked.
Thank you to the speakers, the transcribers, and the curators. Kalenjin on this model is your data, not mine. I'm just the person who fed it to a LoRA and wrote about the result.
The project runs through the KenCorpus consortium, funded by the Bill & Melinda Gates Foundation:
- Maseno University — project lead; Dholuo and Somali collection
- Kabarak University — Kalenjin collection (the data this post is built on)
- United States International University (USIU) — Maasai collection
- Dedan Kimathi University of Technology (DeKUT) and LDRI — Kikuyu collection
Specific people I want to name:
- Dr. Lilian D. A. Wanzare (LinkedIn) — Principal Investigator, Maseno University School of Computing & Informatics, research lead at the Maseno Centre for Applied Artificial Intelligence (MCAAI). Co-founder of KenCorpus. The whole project is hers to lead.
- Dr. Andrew Kiprop Kipkebut — Kabarak University, Department of Computer Science. Led the Kalenjin collection effort. The audio I trained on came through his team.
- Prof. Collins Ouma — Director of Research & Innovation, Maseno University.
And the full list of AfriVoices-KE paper authors, all of whom contributed to making this corpus exist:
Lilian Wanzare, Cynthia Amol, Ezekiel Maina, Nelson Odhiambo, Hope Kerubo, Leila Misula, Vivian Oloo, Rennish Mboya, Edwin Onkoba, Edward Ombui, Joseph Muguro, Ciira wa Maina, Andrew Kipkebut, Alfred Omondi Otom, Ian Ndung'u Kang'ethe, Angela Wambui Kanyi, Brian Gichana Omwenga.
A few other shoulders this stood on:
- OpenAI's Whisper team for releasing
whisper-large-v3-turbounder MIT — the base model everything here is built on. - The HuggingFace PEFT and
transformersmaintainers — most of this code is one or two lines away from examples they ship. - Modal for $30 in starter credits that covered the entire project end-to-end.
- The authors of LoRA (Hu et al. 2021) and its 2024-2026 successors (DoRA, rsLoRA, PiSSA, LoRA+). Their work made parameter-efficient fine-tuning real, and the next iteration of this project will lean on them directly.
- Microsoft Research for releasing Paza. Even though the head-to-head didn't land cleanly, their existence sets the ceiling I'm trying to reach.
- Every practitioner who posted a Whisper fine-tuning notebook, debug trace, or obscure transformers-version-specific bug report on GitHub. Hours of my life saved by your willingness to document your confusion publicly.
Link to Dataset citationDataset citation
If you use or reference the AfriVoices-KE Kalenjin corpus, please cite the paper:
Wanzare, L., Amol, C., Maina, E., Odhiambo, N., Kerubo, H., Misula, L.,
Oloo, V., Mboya, R., Onkoba, E., Ombui, E., Muguro, J., wa Maina, C.,
Kipkebut, A., Otom, A.O., Kang'ethe, I.N., Kanyi, A.W., Omwenga, B.G.
(2025). AfriVoices-KE: A Multilingual Speech Dataset for Kenyan Languages.
arXiv:2604.08448.Dataset homepage: huggingface.co/datasets/Anv-ke/Kalenjin. Project website: maseno.ac.ke/african-next-voices-workshop.
The dataset is released under CC BY 4.0 with a gated-access agreement. Please respect the access agreement and request access directly rather than reusing audio from this project's artifacts. This blog post ships only model weights and predictions text — no raw audio from the dataset is redistributed here.
Link to Lessons logLessons log
- Read the script before you run it. A dtype mismatch cost $0.02. Not much, but the habit scales. On T2 ($2+) or T3 ($10+) it would have hurt.
- HF
datasets.Dataset.from_listplus.map()mangles binary payloads. I built a Dataset from rows containing raw WAV bytes, then called.map()to decode them in a preprocessing step. The Arrow cache layer silently corrupted the bytes. Soundfile threwFormat not recognisedtrying to read them back. The same bytes decoded cleanly outside the datasets pipeline. Fix: ditchdatasets.Datasetentirely for this workload. Use a plaintorch.utils.data.Datasetsubclass with lazy per-example decoding. Simpler, faster, works. - DataLoader workers plus soundfile plus pyarrow fork poorly.
LibsndfileError: <exception str() failed>— the error message itself couldn't be stringified. Classic sign of a C-string that got freed during a process fork.num_workers=0sidesteps it cleanly for now. Revisit for scale. - Don't inherit from
torch.utils.data.Datasetin a file that Modal parses locally. Modal CLI evaluates the whole file on your laptop to build the app graph before shipping to the container. A module-levelimport torchor class inheritance from a torch class will crash if your local venv doesn't have torch. DataLoader duck-types any class with__len__and__getitem__. No inheritance needed. Modal forces you to think about local vs. remote evaluation context in a way other deploy tools don't. load_best_model_at_end=Trueis silently broken with PEFT. The Seq2SeqTrainer reloads frommodel.safetensors; PEFT only savesadapter_model.safetensors. In transformers 4.46 this either errors at end-of-training or silently reloads base weights, making final eval meaningless. Either skip this flag and pick the best adapter manually, or write a callback. I skipped it.- Two reviewers beat one, and one reviewer beats none. After three failed launches, I ran a code-only review agent. Found 6 issues in my pre-review script. Then a doc-cross-referencing review agent. Found 6 MORE issues the first missed, including the
load_best_model_at_endPEFT bug I'd never have found without reading the actual PEFT changelog. A 200-line training script on a fast-moving stack has more surface area than a single read can cover. - Whisper's
enable_input_require_grads()hooks the wrong module. The PEFT docs tell you to call this for gradient checkpointing compat. It works on text models where the first trainable op going backward is an embedding. On Whisper the first op is a conv (encoder.conv1). You need an explicit forward hook on that conv or training will fail withelement 0 of tensors does not require grad. The fix is a 3-line forward hook. You won't find it in the standard PEFT docs. You need to look at actual Whisper LoRA notebooks (Vaibhavs10/fast-whisper-finetuning was my source). bf16=Trueautocast wraps training, NOTSeq2SeqTrainer.prediction_step. Under the hood,bf16=Truein TrainingArguments enablestorch.autocast(cuda, bf16)for the training forward/backward. Eval goes throughSeq2SeqTrainer.prediction_stepwhich callsmodel.generate(), andgenerate()is NOT wrapped in autocast. If your model weights are bf16 and your collator outputs fp32 features, training works (autocast casts inputs) but epoch-end eval crashes with a dtype mismatch at conv1. Fix: subclass Seq2SeqTrainer and wrapprediction_stepwith your own autocast context. Four lines.- Whisper's
bos_token_idis not itsdecoder_start_token_id. Many LoRA fine-tuning cookbooks copy-paste a collator that strips duplicate BOS. For Whisper specifically,bos_token_id = <|endoftext|>anddecoder_start_token_id = <|startoftranscript|>. The strip silently fails if you check the wrong one. Worth a closer look at official HF scripts. - First samples lie. Always query the metadata column. The first five random clips I pulled were all Healthcare. Twenty lines of Python on the
domaincolumn showed Healthcare was actually 11% of scripted and 4% of unscripted. Sampling alone, even with a uniform RNG, can land you in a domain pocket — read the metadata if you can. - Language-token choice for unseen languages is a free hyperparameter. I picked
sw(Swahili) because Kalenjin speakers in Kenya also speak Swahili, and both share Bantu-ish phonology.enorhi(Hindi, another catch-all) are reasonable alternatives. Worth an A/B once the pipeline works.