![]()
The "low-rank" part of LoRA is the trick that makes the adapter small.
To understand it, we need three terms:
- matrix
- weight update
- rank
We will keep the math simple, but not fake.
Link to Neural Networks Use MatricesNeural Networks Use Matrices
Inside a model, many layers use weight matrices.
A matrix is just a grid of numbers. In a model, those numbers transform information.
For a simplified layer, you can imagine:
output = W x inputW is the weight matrix.
During full fine-tuning, the model changes W.
You can describe that as:
new W = old W + updateThat update can be huge, because W can be huge.
Link to LoRA Does Not Learn The Full UpdateLoRA Does Not Learn The Full Update
LoRA says:
Instead of learning one full update matrix, learn two smaller matrices whose product acts like the update.
In common notation:
Delta W = B @ ADelta W means "the change to W."
A and B are the LoRA matrices.
They are smaller than the full update because they use a small inner dimension called rank, usually written as r.
Link to What Rank Means HereWhat Rank Means Here
Rank is a real linear algebra term. In this context, you can think of it as the number of independent directions the adapter can use to describe the update.
If r is small, the adapter is tiny but less expressive.
If r is larger, the adapter can express more complicated changes but uses more memory and compute.
So rank is a capacity knob.
Very rough intuition:
small r = cheaper, less expressive
large r = more expensive, more expressiveThe useful surprise behind LoRA is that many fine-tuning updates appear to work well with a relatively low rank.
Thinking Machines adds a practical way to say this:
LoRA is not only useful because "low rank" is philosophically special. It is useful because it creates an efficient low-dimensional path through the parameter space.
That means the adapter gives training a smaller set of knobs to turn. If the job only needs a small amount of new information, those knobs can be enough.
Link to A Concrete Shape ExampleA Concrete Shape Example
Suppose a layer has a weight matrix with shape:
4096 x 4096A full update would also be:
4096 x 4096That is more than 16 million numbers.
With LoRA, if rank r = 8, the two matrices are shaped like:
A: 8 x 4096
B: 4096 x 8Together, those are about 65 thousand numbers.
That is massively smaller than 16 million.
This is the whole economic reason LoRA works: the update is represented through a bottleneck.
Link to The Bottleneck Is The PointThe Bottleneck Is The Point
The low-rank bottleneck forces the adapter to learn a compact change.
That can be good:
- fewer trainable parameters
- less GPU memory
- smaller saved adapter files
- easier to maintain many adapters
But it is also a constraint:
- the adapter may not capture every possible change
- very complex tasks may need a larger rank
- bad data cannot be rescued just by LoRA
Low-rank is not magic. It is a useful assumption.
Link to Capacity: The Adapter Can Run Out Of RoomCapacity: The Adapter Can Run Out Of Room
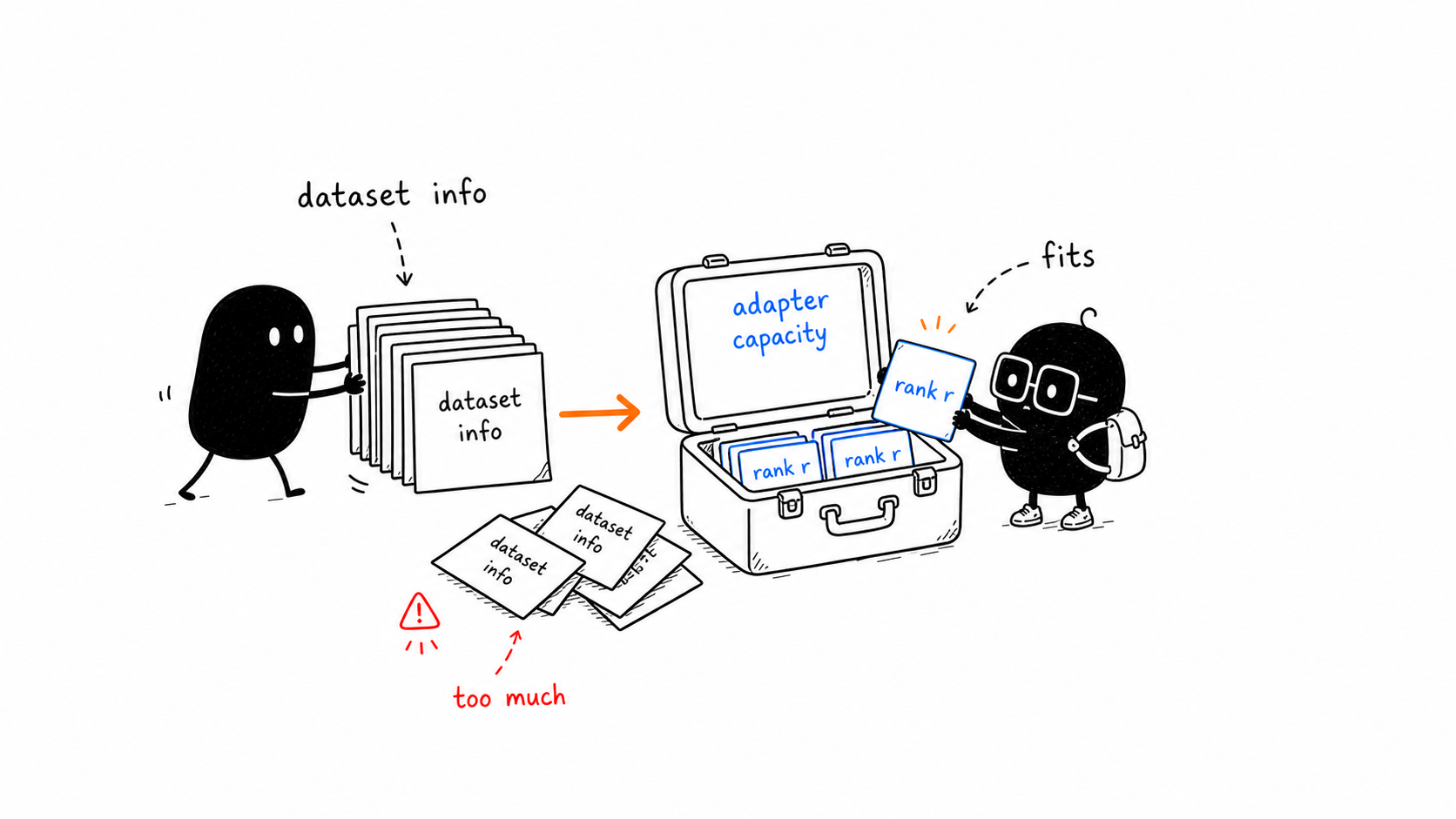
Thinking Machines uses the word capacity a lot when explaining LoRA.
Capacity means: how much useful information the adapter can absorb.
Rank contributes to capacity because higher rank gives the adapter more trainable parameters. Dataset size also matters because a larger dataset may contain more information for the model to learn.
A good mental model:
adapter capacity should be large enough for the information in the training dataIf the dataset exceeds LoRA capacity, performance may fall behind full fine-tuning. It is not always a hard wall where loss stops improving. It can look like worse training efficiency: LoRA keeps learning, but more slowly or less effectively than full fine-tuning.
This is why rank should be tied to the job, not picked like a lucky number. A tiny adapter can be great for a focused behavior shift. A larger or more information-rich dataset may need more rank, more target modules, or full fine-tuning.
Link to LoRA ScalingLoRA Scaling
You may see a setting called lora_alpha.
LoRA implementations often scale the adapter update, commonly like:
scaled update = (alpha / r) * B @ AYou do not need to memorize the exact scaling yet.
Just know:
rcontrols adapter rank/capacityalphacontrols update strength- together they affect how strongly the adapter influences the base model
Link to Terms To LearnTerms To Learn
-
Matrix: A rectangular grid of numbers.
-
Weight matrix: A model matrix that transforms hidden information inside a layer.
-
Delta W: The learned update added to an existing weight matrix.
-
Rank r: The low-rank bottleneck size. It controls adapter capacity.
-
A and B matrices: The two LoRA matrices whose product forms the update.
-
Alpha: A scaling factor that controls the strength of the LoRA update.
-
Capacity: The amount of task information the adapter can represent. Rank, target modules, and dataset size all affect whether capacity is enough.
Link to Check YourselfCheck Yourself
Try explaining this without looking:
- What is
Delta W? - Why does LoRA use two smaller matrices?
- What does rank
rcontrol? - What is the tradeoff between small rank and large rank?
- What does it mean for a dataset to exceed adapter capacity?
Link to Chapter SummaryChapter Summary
LoRA replaces a huge trainable update with two smaller matrices, A and B. Their product creates a low-rank update. Rank r controls adapter capacity, but the right rank depends on how much information the training data asks the adapter to absorb.