LoRA stands for Low-Rank Adaptation.
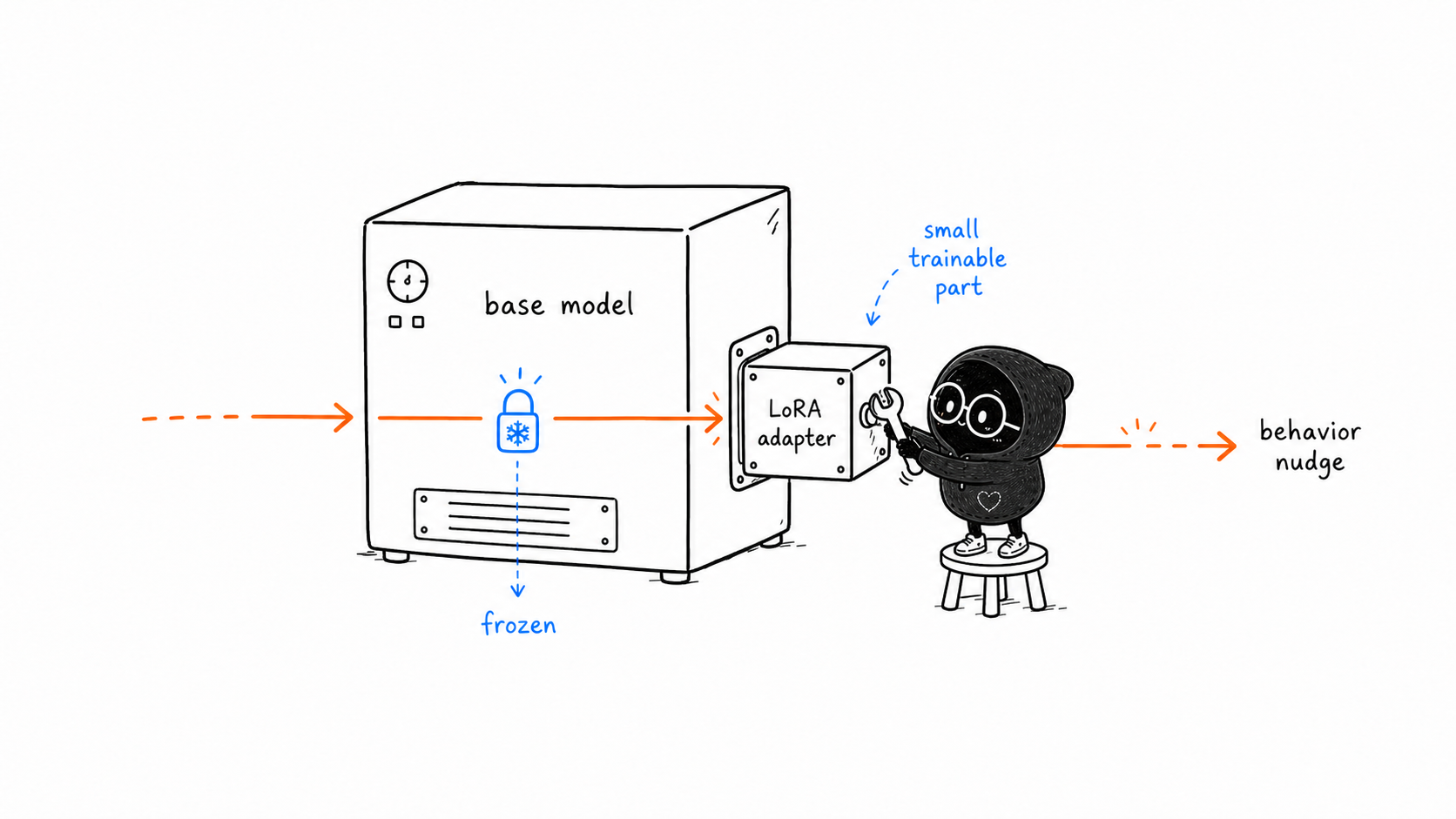
It is a technique for adapting a pretrained model without updating all of the model's original parameters. Instead of changing the whole base model, LoRA freezes the base model and adds small trainable pieces called adapters.
Think of a large base model as a giant machine that already knows a lot. It has learned language patterns, facts, reasoning shapes, style patterns, and task behavior from its original training. Full fine-tuning opens that whole machine and adjusts many internal parts.
LoRA does something smaller and more focused:
Keep the big machine frozen. Attach a small adapter that learns the difference between the old behavior and the behavior you want.
That difference is the key idea.
Link to What Problem LoRA SolvesWhat Problem LoRA Solves
Large models are expensive to fine-tune because their parameter count is huge.
If a model has billions of parameters, full fine-tuning usually means:
- you need memory for the base weights
- you need memory for gradients
- you need memory for optimizer states
- you need to store a large fine-tuned copy afterward
LoRA reduces that burden by training only a small number of new parameters.
The base model stays fixed. The adapter learns a compact update.
Link to The Base Model Is FrozenThe Base Model Is Frozen
When we say the base model is frozen, we mean its original weights are not changed during LoRA training.
The training loop still uses the base model. Data still flows through it. The model still produces outputs. But when the optimizer updates parameters, it only updates the LoRA adapter weights.
This matters because the expensive, general knowledge in the base model stays intact.
LoRA is not "teaching from zero." It is more like steering something that already works.
Link to The Adapter Learns A DirectionThe Adapter Learns A Direction
The LoRA adapter does not need to relearn all of language or all of vision or all of coding.
It learns a smaller adjustment:
- answer in this style
- classify this kind of document
- understand this domain vocabulary
- follow this workflow
- prefer this output format
That is why LoRA can work with far fewer trainable parameters than full fine-tuning.
Link to Adapter Does Not Mean "Prompt"Adapter Does Not Mean "Prompt"
This is important:
A LoRA adapter is not a prompt.
A prompt is text you give the model at inference time.
A LoRA adapter is trained weights. It changes how selected model layers behave when the model runs.
Prompts guide behavior through context. Adapters change behavior through learned parameters.
Link to Why The Name "Low-Rank Adaptation"?Why The Name "Low-Rank Adaptation"?
The name has two parts:
-
Low-rank: The adapter represents the model update using smaller matrices instead of a full large matrix.
-
Adaptation: The adapter changes the model's behavior for a new task, style, or domain.
You do not need to master matrix algebra yet. For now, hold this:
LoRA assumes the useful update can be described by a smaller internal structure than a full fine-tuning update.
That smaller structure is why LoRA is practical.
Link to Where LoRA Is UsedWhere LoRA Is Used
LoRA is common in:
- large language model fine-tuning
- image generation model customization
- domain adaptation
- style adaptation
- instruction tuning experiments
- cases where people want many small task-specific adapters
One base model can have many LoRA adapters.
That is one of the nicest practical properties: instead of storing ten full fine-tuned models, you can store one base model and ten small adapters.
Link to Terms To LearnTerms To Learn
-
Frozen weights: Model weights that do not change during training.
-
Trainable parameters: Parameters the optimizer is allowed to update.
-
Adapter weights: The new small weights added by LoRA.
-
Parameter-efficient fine-tuning: A family of methods that adapt models by training relatively few parameters.
Link to Check YourselfCheck Yourself
If you can answer these, you have the core idea:
- What stays frozen in LoRA?
- What actually gets trained?
- Why is LoRA smaller than full fine-tuning?
- Why is a LoRA adapter different from a prompt?
Link to Chapter SummaryChapter Summary
LoRA adapts a pretrained model by freezing the base model and training small adapter weights. The adapter learns a compact behavior change, which makes fine-tuning cheaper to train, store, and swap.