![]()
LoRA makes fine-tuning cheaper by training small adapters.
QLoRA goes one step further:
Keep the base model quantized to save memory, then train LoRA adapters on top.
The "Q" means quantized.
Link to What Quantization MeansWhat Quantization Means
Model weights are numbers.
Normally, training and inference may use formats like 16-bit floating point. Quantization stores weights with fewer bits, such as 8-bit or 4-bit.
Fewer bits means less memory.
The tradeoff is that quantization can introduce approximation error. The model is compressed, so you must watch quality.
Link to What QLoRA DoesWhat QLoRA Does
QLoRA keeps the pretrained base model in a low-bit quantized format, commonly 4-bit, and trains LoRA adapters while the base remains frozen.
The high-level picture:
quantized frozen base + trainable LoRA adapterThe base model becomes cheaper to fit in memory.
The adapter remains small and trainable.
This makes fine-tuning larger models possible on smaller hardware than full fine-tuning would require.
Link to Why This MattersWhy This Matters
For large models, memory is often the wall.
You may have enough data and enough motivation, but not enough GPU memory to train the whole model.
LoRA reduces trainable parameters.
QLoRA reduces the memory footprint of the frozen base model.
Together, they make adaptation more accessible.
Link to The Main TradeoffsThe Main Tradeoffs
QLoRA is useful, but it is still a tradeoff.
-
Memory: Usually much better than full fine-tuning.
-
Speed: Can vary depending on hardware, kernels, and implementation.
-
Quality: Often strong, but quantization and adapter settings still matter.
-
Complexity: More moving pieces than basic LoRA: quantization type, compute dtype, optimizer choices, and adapter settings.
Link to Rank, Memory, And QualityRank, Memory, And Quality
Rank r still matters in QLoRA.
If rank is too small, the adapter may not have enough capacity.
If rank is too large, you spend more memory and compute.
The useful mental model:
rank is the adapter's bandwidthA tiny bandwidth is cheap but may not carry enough signal.
A larger bandwidth can carry more signal but costs more.
Link to When LoRA Is A Good FitWhen LoRA Is A Good Fit
LoRA is often a good fit when:
- you have a strong base model
- you want a task, style, or domain adaptation
- you need cheaper training than full fine-tuning
- you want to store multiple small variants
- you can collect focused examples
Thinking Machines calls the most favorable zone the low-regret regime: settings where LoRA performs similarly to full fine-tuning while being cheaper and operationally easier.
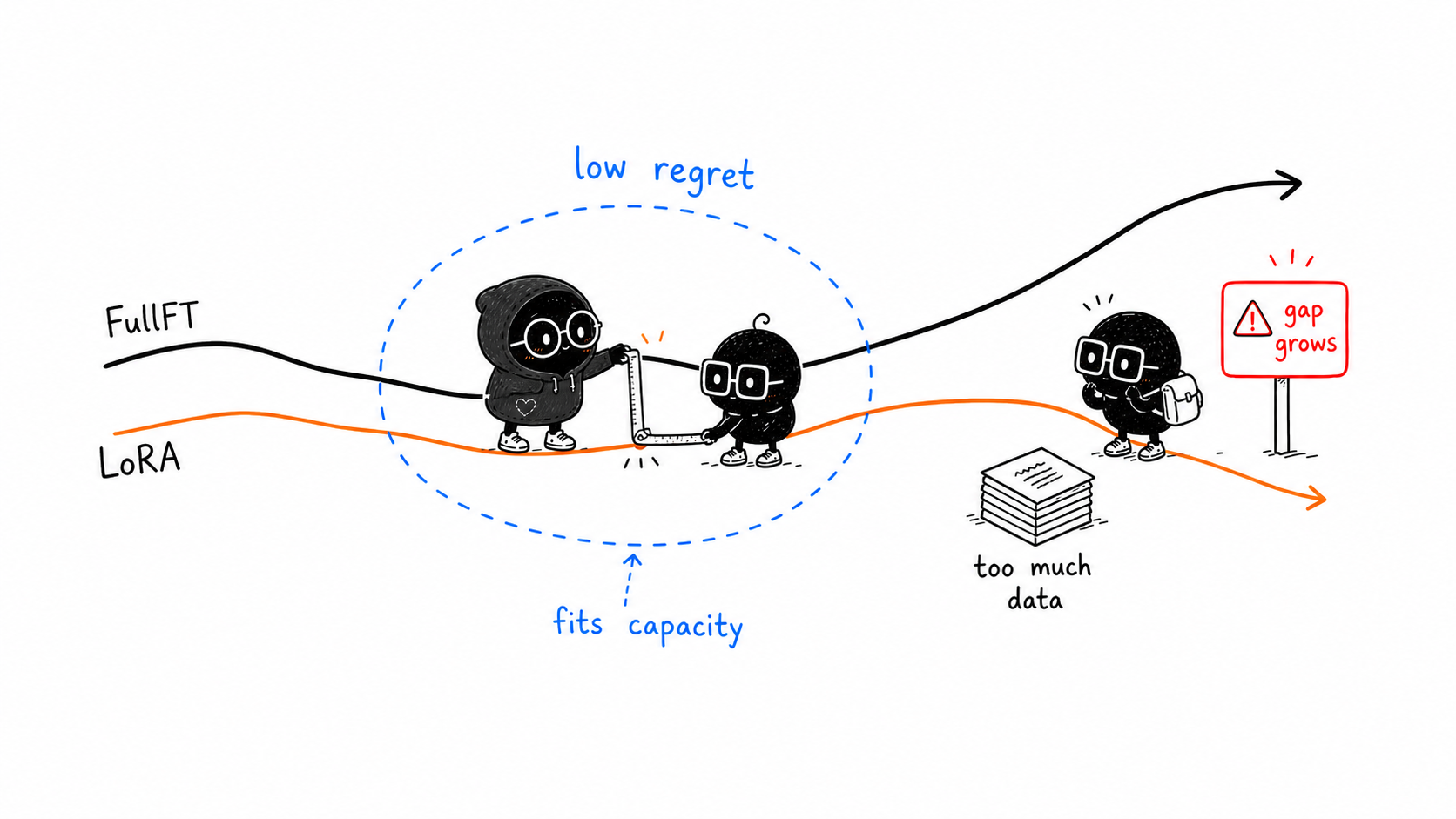
Their current guidance is that LoRA can match full fine-tuning for reinforcement learning and for supervised fine-tuning on small-to-medium instruction-tuning or reasoning datasets, assuming the important details are right.
Link to When LoRA May Not Be EnoughWhen LoRA May Not Be Enough
LoRA may struggle when:
- the base model is too weak for the target behavior
- the task requires deep new capabilities
- the training data is poor
- the adapter rank is too low
- the target modules are poorly chosen
- you expect it to memorize a large knowledge base perfectly
- the dataset is large enough to exceed adapter capacity
- you use a full-fine-tuning learning rate without retuning
LoRA is an adaptation tool. It is not a replacement for retrieval, better data, better prompting, evaluation, or choosing the right base model.
Link to A Better Fit QuestionA Better Fit Question
Instead of asking:
Is LoRA always as good as full fine-tuning?
Ask:
Is my task in a regime where the adapter has enough capacity for the information I need to learn?
That question is more useful.
Small or focused post-training often fits LoRA well.
Very large supervised datasets may ask the adapter to absorb more information than its low-rank parameters can comfortably represent.
Reinforcement learning can sometimes need surprisingly little adapter capacity because each episode may provide a small amount of learning signal compared with token-by-token supervised learning.
This is the most mature way to think about LoRA:
LoRA is not always worse.
LoRA is not always enough.
LoRA is best when the adapter capacity matches the learning signal.Link to A Practical Decision PathA Practical Decision Path
Use this simple path:
- Start with a strong base model.
- Try prompting first.
- If prompting is not enough, consider LoRA.
- If memory is tight, consider QLoRA.
- Evaluate with examples that look like real use.
- Adjust rank, target modules, data quality, and training length.
Link to Terms To LearnTerms To Learn
-
Quantization: Storing weights with fewer bits to save memory.
-
4-bit base: A base model stored in 4-bit precision.
-
QLoRA: Quantized LoRA: train LoRA adapters on top of a quantized frozen model.
-
Compute dtype: The numerical format used during computation, which may differ from storage format.
-
Evaluation set: Examples held out to test whether training actually improved behavior.
-
Low-regret regime: A setting where LoRA gives performance close to full fine-tuning while keeping LoRA's efficiency benefits.
-
Training efficiency: How quickly loss improves for a given amount of data and compute.
Link to Check YourselfCheck Yourself
Answer these:
- What does QLoRA add on top of LoRA?
- Why does quantization save memory?
- What can go wrong if rank is too small?
- Why should you evaluate with realistic examples?
- What does "low-regret regime" mean?
Link to Chapter SummaryChapter Summary
QLoRA combines quantization with LoRA: the base model is stored in a memory-saving low-bit format, while small LoRA adapters are trained. LoRA can be close to full fine-tuning in the right regime, but rank, data size, learning rate, batch size, target modules, and evaluation still matter.